In a significant shift for the artificial intelligence industry, Cohere AI Labs has announced the release of Tiny Aya, a sophisticated family of small language models (SLMs) designed to provide high-tier multilingual capabilities on consumer-grade hardware. While the prevailing trend in large language model (LLM) development has focused on scaling parameters into the hundreds of billions, Tiny Aya utilizes a compact 3.35-billion-parameter architecture to deliver state-of-the-art performance in translation, summarization, and natural language generation across 70 distinct languages. This release marks a pivotal moment in the democratization of AI, moving powerful multilingual tools from massive data centers directly onto local devices such as smartphones and laptops.
The Tiny Aya initiative is the latest evolution of Cohere’s broader Aya project, a multi-year effort dedicated to bridging the "digital divide" in AI, where English and a handful of high-resource languages often receive disproportionate attention. By optimizing for a smaller parameter count without sacrificing linguistic breadth, Cohere aims to provide a solution for regions with limited internet connectivity or for users who prioritize data privacy through offline execution. The release comprises five distinct models: Tiny Aya Base, the foundation for further fine-tuning; Tiny Aya Global, a balanced general-purpose instruction-tuned model; and three specialized regional variants—Earth, Fire, and Water—which are optimized for specific linguistic clusters across Africa, Asia, and Europe.
Technical Architecture and Training Methodology
The foundation of Tiny Aya lies in a dense, decoder-only Transformer architecture, a design choice that prioritizes efficiency and low-latency inference. The model features 32 transformer layers and 32 attention heads, with a hidden dimension size of 3,072. To ensure the model remains stable during high-intensity training and avoids common pitfalls like gradient explosion, the engineering team implemented SwiGLU activation functions and took the unconventional step of removing all biases from the dense layers.
The pretraining phase for Tiny Aya involved a massive corpus of 6 trillion tokens, sourced from a diverse array of multilingual web data, code, and curated academic datasets. Cohere employed a Warmup-Stable-Decay (WSD) learning rate schedule, which has become a preferred method for training stable SLMs. This approach allows the model to rapidly ingest information during the warmup phase, maintain a high learning rate for the bulk of the training to ensure broad knowledge acquisition, and finally undergo a controlled "decay" or annealing phase to sharpen its precision and reasoning capabilities.
To address the inherent difficulty of training a small model to handle 70 languages—many of which have limited digital footprints—Cohere utilized an advanced post-training pipeline known as FUSION. This methodology relies on a synthetic data generation system where larger, more capable models are used to create high-quality training examples in low-resource languages. These examples are then used to "teach" the smaller Tiny Aya model, effectively transferring the reasoning capabilities of a massive LLM into a 3.3B parameter container.

Specialized Regional Variants and SimMerge Technology
One of the most innovative aspects of the Tiny Aya release is the introduction of regional variants. Recognizing that a single 3.3B parameter model may struggle to reach "expert" status in 70 languages simultaneously, Cohere developed a strategy to specialize the weights for specific geographic and linguistic groups.
- Tiny Aya Global: The flagship instruction-tuned model, designed to provide balanced performance across all 70 supported languages. It serves as the primary choice for users requiring a versatile, multi-purpose assistant.
- Tiny Aya Earth: Specifically optimized for languages spoken across Africa and West Asia. This model addresses the unique grammatical structures and nuances of languages like Swahili, Amharic, and Arabic.
- Tiny Aya Fire: Focused on the linguistic diversity of South Asia, providing enhanced performance for Hindi, Bengali, Tamil, and other regional dialects that are often underserved by Western-centric models.
- Tiny Aya Water: Tailored for the Asia-Pacific region and Europe, ensuring high-fidelity outputs for languages ranging from Japanese and Korean to French and German.
To create these variants, Cohere utilized "SimMerge," a proprietary model-merging technique. SimMerge allows developers to take specialized models trained on different subsets of data and fuse them into a single set of weights without the catastrophic forgetting typically associated with sequential fine-tuning. This ensures that while a model like Tiny Aya Fire is optimized for South Asian languages, it does not lose its fundamental reasoning or general knowledge capabilities.
Benchmarking Performance Against Industry Giants
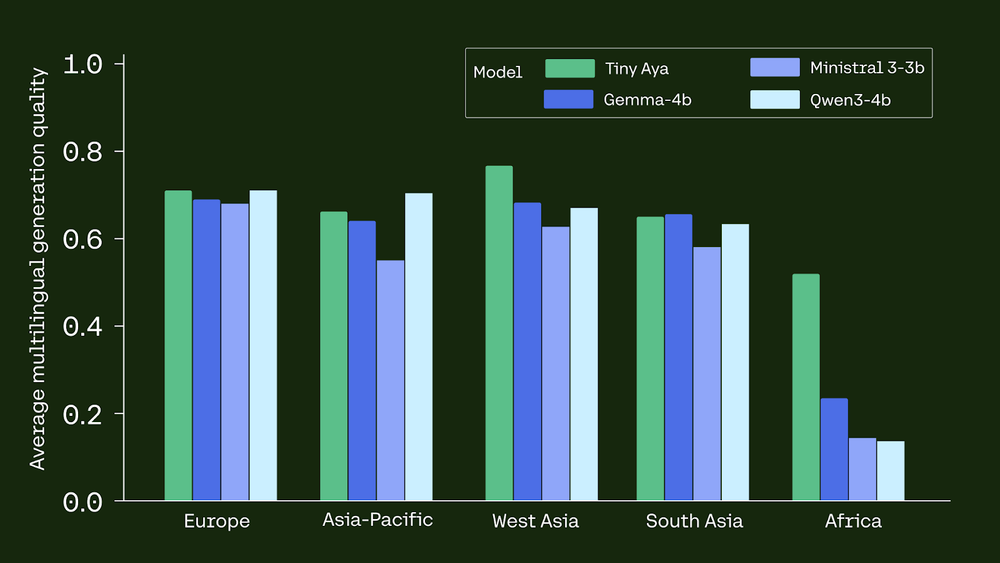
The performance data released by Cohere AI Labs suggests that Tiny Aya Global is punching well above its weight class. In rigorous multilingual benchmarks, the 3.35B model consistently outperformed competitors that are two to three times its size. For instance, in the Multilingual Grade School Math (MGSM) benchmark—a key indicator of a model’s ability to reason across different languages—Tiny Aya Global surpassed Meta’s Llama 3 8B and Google’s Gemma 2 9B.
In translation tasks, Tiny Aya demonstrated a superior ability to maintain semantic meaning and cultural nuance, particularly in languages that are typically marginalized in AI training sets. The efficiency of the model is perhaps its most striking feature; by achieving these results with only 3.35 billion parameters, Tiny Aya offers a significantly higher "intelligence-per-watt" ratio than larger alternatives. This makes it an ideal candidate for enterprise applications where operational costs and carbon footprints are critical considerations.
On-Device Deployment and Quantization Efficiency
A primary objective of the Tiny Aya project is to enable local AI execution. To facilitate this, Cohere has optimized the model for various quantization schemes. Using 4-bit quantization (specifically the Q4_K_M method), the model’s memory footprint is reduced to just 2.14 GB. This allows the model to run comfortably on modern smartphones, tablets, and entry-level laptops without requiring specialized GPU clusters or high-bandwidth cloud connections.
Technical reports indicate that the transition from full precision to 4-bit quantization results in a negligible 1.4-point drop in generation quality. This minimal loss in performance is a breakthrough for edge computing, as it proves that highly compressed models can still maintain the integrity of their outputs. For users in the legal, medical, or security sectors, the ability to run such a capable model locally ensures that sensitive data never leaves the device, providing a level of privacy that cloud-based AI cannot match.
Historical Context and the Evolution of the Aya Project
The launch of Tiny Aya is the culmination of years of open-science research conducted by Cohere For AI, the company’s non-profit research arm. The project began with "Aya 101," a massive collaborative effort involving over 3,000 independent researchers from 119 countries. This collaboration resulted in the creation of the world’s largest multilingual instruction-tuning dataset.
Following the success of Aya 101, Cohere released "Aya Expanse," which pushed the boundaries of how models could generalize across languages. Tiny Aya represents the "distillation" of these years of research into a form factor that is accessible to the average consumer. Chronologically, this release follows a trend in the AI industry toward "small" being the new "large," as companies like Microsoft (with the Phi series) and Mistral (with the Ministral series) also pivot toward efficient, high-performance SLMs.
Broader Implications and Industry Reactions
The release of Tiny Aya has sparked discussions among AI ethicists and developers regarding the future of the digital language divide. By providing a model that is both open-weight and high-performing in 70 languages, Cohere is lowering the barrier to entry for developers in the Global South to build localized AI applications.
Industry analysts suggest that Tiny Aya could disrupt the current SaaS (Software as a Service) model for AI. If developers can embed a high-quality multilingual assistant directly into their apps for free, the reliance on expensive API calls to providers like OpenAI or Anthropic may diminish for many common use cases. Furthermore, the regional variants (Earth, Fire, Water) offer a blueprint for how AI can be customized to respect local cultural and linguistic contexts rather than imposing a "one-size-fits-all" Western perspective.
As AI continues to integrate into daily life, the demand for models that are fast, private, and linguistically diverse is expected to grow. Tiny Aya stands at the forefront of this movement, proving that massive scale is not the only path to intelligence. With its 3.35 billion parameters, Tiny Aya is not just a technical achievement; it is a tool for global communication, designed to ensure that the benefits of the AI revolution are shared by all, regardless of the language they speak or the hardware they own.
Cohere has made the model weights, technical reports, and a playground environment available to the public via Hugging Face, inviting the global research community to build upon this new foundation for multilingual edge computing.