

The rapid scaling of artificial intelligence models has encountered a formidable physical barrier: the "memory wall." As transformer-based architectures grow deeper to handle increasingly complex tasks in vision and language, the hardware requirements for training these models have surged to levels that challenge even the most advanced data centers. In a significant move to address this bottleneck, researchers from Sakana AI and the University of Tokyo have unveiled DiffusionBlocks, a novel training framework that allows deep neural networks to be trained one block at a time. By partitioning a network into $B$ independently trainable blocks, the framework reduces the memory footprint of parameters, gradients, and optimizer states by a factor of $B$, all while maintaining performance levels comparable to traditional end-to-end backpropagation.
The Persistent Challenge of Memory in Neural Training
For decades, the gold standard for training neural networks has been end-to-end backpropagation. This process requires the system to store intermediate activations for every single layer during the forward pass so they can be utilized to calculate gradients during the backward pass. Consequently, memory consumption grows linearly with the depth of the network. In the era of Large Language Models (LLMs) and high-resolution Diffusion Transformers (DiTs), this linear growth has become a primary constraint on model size and training accessibility.
While existing techniques like activation checkpointing have offered some relief by recomputing activations on demand—thereby trading computational time for memory—they do not address the substantial memory requirements of the weights themselves. When using the industry-standard Adam optimizer, every layer requires memory for the parameters, the gradients, and two additional optimizer states: momentum and variance. This effectively quadruples the memory requirement relative to the parameter count of each layer. For a model with billions of parameters, this overhead necessitates massive clusters of high-memory GPUs, often pricing out smaller research institutions and independent developers.
The Conceptual Leap: Residual Networks as Diffusion Steps
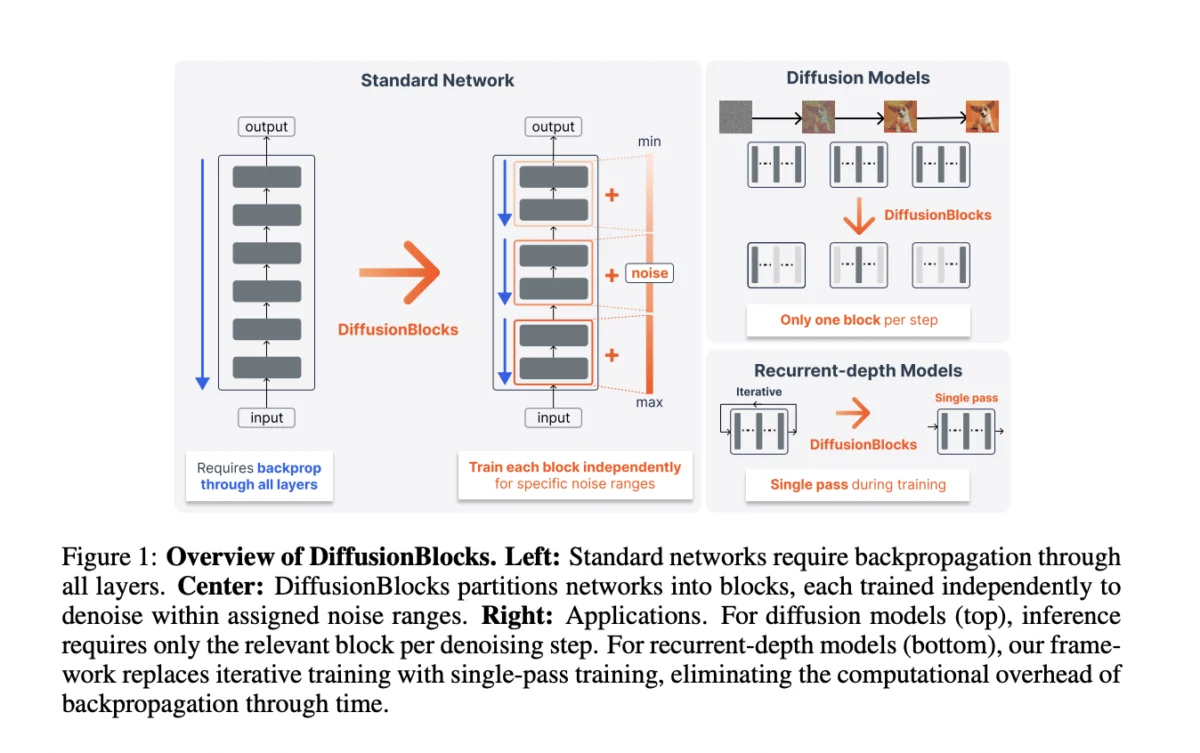
The breakthrough behind DiffusionBlocks lies in a sophisticated mathematical reinterpretation of how information flows through a residual network (ResNet). The research team, led by Makoto Shing, Masanori Koyama, and Takuya Akiba, built upon the established observation that residual connections—where the input to a layer is added to its output—can be viewed as a discrete approximation of an Ordinary Differential Equation (ODE). Specifically, the update rule $zl = zl-1 + f_thetal(zl-1)$ mirrors the Euler discretization used in numerical physics.
The Sakana AI team extended this logic to the realm of generative modeling. They demonstrated that these residual updates correspond specifically to the probability flow ODE found in score-based diffusion models, particularly under the Variance Exploding (VE) formulation. In this context, a stack of residual blocks can be interpreted as a series of discretized denoising steps.
In traditional score-based diffusion, the objective is to learn to reverse a process that gradually adds noise to data. Crucially, the "score matching" objective in these models can be optimized independently for different noise levels. DiffusionBlocks leverages this property by treating different sections of a neural network as specialized denoising modules assigned to specific noise regimes. Because each block targets a local objective based on its assigned noise level, the need for global, end-to-end backpropagation is eliminated. Each block can be trained in isolation, requiring no communication with other blocks during the training phase.
Implementation: The Three-Step Conversion Process
To transform a standard residual or transformer-based architecture into a DiffusionBlocks-compatible model, the researchers outlined a systematic three-step procedure:
- Block Partitioning: An $L$-layer network is divided into $B$ contiguous blocks. For instance, a 12-layer Vision Transformer (ViT) might be split into three blocks of four layers each.
- Noise Range Assignment: The researchers define a total noise range, typically spanning from a minimum noise level ($sigmamin$) to a maximum level ($sigmamax$). This range is then partitioned into $B$ distinct intervals, with one interval assigned to each block.
- Noise Conditioning: Each block is modified to accept a noisy version of the target data as its input. To ensure the block knows which specific noise level it is currently processing within its assigned range, the researchers implement noise-level conditioning, often utilizing Adaptive Layer Norm (AdaLN) layers.
During the training process, the system samples a single block for each iteration. Only the parameters and gradients for that specific block are loaded into memory, while the other $B-1$ blocks remain inactive. This results in a memory reduction proportional to the number of blocks used.
Optimizing through Equi-probability Partitioning
A critical technical nuance identified by the research team involves how the noise range is divided. Initially, a naive approach might suggest a uniform partition, where the noise range is split into equal mathematical intervals. However, the researchers found that this ignores the "difficulty" curve of denoising. In a standard log-normal training distribution, intermediate noise levels often contribute more significantly to the overall quality of the generated output than extreme low or high noise levels.
To solve this, DiffusionBlocks employs "equi-probability partitioning." Boundaries between blocks are calculated so that each block handles an equal amount of the total probability mass of the noise distribution. This ensures that every block receives an equal amount of "training attention" relative to the importance of the noise levels it manages. In ablation studies conducted on the CIFAR-10 dataset using a Diffusion Transformer (DiT-S/2), equi-probability partitioning achieved a Fréchet Inception Distance (FID) of 38.03, significantly outperforming the 43.53 score achieved by uniform partitioning.

Comparative Performance and Experimental Data
The researchers validated DiffusionBlocks across five distinct architectures and three task categories: image classification, image generation, and language modeling. The results indicated that the block-wise approach consistently matched or even exceeded the performance of end-to-end baselines while providing significant memory savings.
In vision tasks using a 12-layer ViT on the CIFAR-100 dataset, DiffusionBlocks achieved 59.30% accuracy compared to the 60.25% baseline, while utilizing only one-third of the memory ($B=3$). More impressively, on the ImageNet $256 times 256$ benchmark using a 24-layer DiT-L/2, DiffusionBlocks actually improved the FID score to 10.63, down from the baseline of 12.09.
The framework also showed remarkable results in language modeling. When applied to the LM1B dataset with an Autoregressive (AR) Transformer, DiffusionBlocks achieved a MAUVE score of 0.71, surpassing the baseline of 0.50. On the OpenWebText dataset, the results were more closely matched, with DiffusionBlocks scoring 0.82 against the baseline’s 0.85.
The team also compared their method against the "Forward-Forward" algorithm proposed by Geoffrey Hinton. On CIFAR-100, the Forward-Forward algorithm struggled, reaching only 7.85% accuracy, whereas DiffusionBlocks remained competitive with backpropagation. This disparity underscores the strength of the score-matching objective over more ad-hoc local objectives.
Case Study: The Huginn Recurrent-Depth Model
One of the most striking applications of DiffusionBlocks was its integration with Huginn, a model that applies a single recurrent block multiple times (averaging 32 iterations) during inference. Traditionally, training such a model requires truncated Backpropagation Through Time (BPTT), which is computationally expensive and memory-intensive.
By applying the DiffusionBlocks framework, the researchers were able to replace the multi-step BPTT with a single forward pass per training step. While this required a slightly longer training schedule (15 epochs versus 5), the reduction in iterations per step led to an overall compute reduction of approximately 10 times. Despite this massive reduction in training effort, the model achieved a MAUVE score of 0.70 on the LM1B dataset, significantly higher than the 0.49 baseline.
Implications for the AI Industry
The implications of DiffusionBlocks extend beyond mere academic interest. As the AI industry grapples with the high costs of hardware, a method that can reduce training memory by 3x or 4x without sacrificing performance could democratize the development of sophisticated models.
- Hardware Accessibility: DiffusionBlocks could allow researchers to train larger models on consumer-grade hardware or smaller GPU clusters, reducing the reliance on massive H100 or B200 arrays.
- Inference Efficiency: For diffusion-based models, the framework offers a "free" benefit at inference time. Because each denoising step only requires the activation of one block, a 12-layer model partitioned into three blocks effectively operates as a 4-layer model during each step of the generation process, leading to a 3x speedup in compute efficiency.
- Modular Scaling: The independent nature of the blocks suggests a future where models can be scaled by adding more blocks that are trained separately and then "stacked" together, potentially simplifying the engineering of massive-scale systems.
Limitations and Future Outlook
Despite its successes, DiffusionBlocks is not a universal solution. Its primary limitation is the requirement for residual connections; architectures that lack these pathways cannot currently benefit from the framework. Additionally, because the method introduces an extra forward pass (sampling noise levels) and requires specialized noise conditioning, there is a minor trade-off in architectural complexity.
The researchers also noted that while the results were largely positive, performance on certain datasets like OpenWebText showed slight degradation in specific metrics, suggesting that the "one-size-fits-all" noise schedule may need further tuning for diverse data types.
The work by Sakana AI and the University of Tokyo represents a shift in the philosophy of neural network training. By moving away from the "global" necessity of backpropagation and toward a "local" objective rooted in diffusion theory, DiffusionBlocks provides a viable path forward for the next generation of deep learning models. As the project moves into the open-source community via its GitHub repository, the broader AI field will likely begin exploring how this block-wise paradigm can be applied to even larger and more varied architectures.