The rapid evolution of Large Language Models (LLMs) has consistently grappled with a fundamental engineering trade-off: the choice between the immediate flexibility of In-Context Learning (ICL) and the long-term efficiency of Supervised Fine-Tuning (SFT). While ICL allows models to perform new tasks simply by providing examples in a prompt, it imposes a heavy tax on computational resources, specifically through increased latency and memory consumption as the context window grows. Conversely, fine-tuning offers efficient inference but requires time-consuming backpropagation and significant data for every new task. Tokyo-based research lab Sakana AI has proposed a paradigm shift to resolve this tension through the introduction of two novel hypernetworks: Text-to-LoRA (T2L) and Doc-to-LoRA (D2L).
These frameworks utilize meta-learning to generate Low-Rank Adaptation (LoRA) matrices in a single forward pass. By shifting the heavy lifting to a one-time meta-training phase—a process known as cost amortization—Sakana AI enables LLMs to internalize new tasks or massive documents instantly. This breakthrough suggests a future where models can be "reprogrammed" or "updated" with new knowledge in milliseconds, bypassing the traditional constraints of both context windows and gradient-based training.
The Engineering Bottleneck: The High Cost of Context
To understand the significance of Sakana AI’s contribution, one must first analyze the current limitations of LLM deployment. Modern AI development faces a "memory wall" and a "latency ceiling." When using In-Context Learning, the model must process the entire prompt—including instructions and examples—every time a query is made. This leads to a massive Key-Value (KV) cache, which consumes VRAM and slows down the time-to-first-token. For enterprises handling thousands of documents, the cost of repeatedly "reading" the same context for different queries becomes prohibitive.
Supervised Fine-Tuning and Context Distillation (CD) offer alternatives by embedding knowledge directly into the model’s weights. However, these methods are rigid. Fine-tuning requires expensive GPU hours for backpropagation, making it impossible to adapt a model to a new user or a new document in real-time. Sakana AI’s T2L and D2L address this by treating the adaptation process as a prediction problem rather than an optimization problem. Instead of updating weights through iterative training, a lightweight "hypernetwork" looks at a task description or a document and predicts exactly what the LoRA weights should be to make the LLM understand that specific input.
Text-to-LoRA (T2L): Zero-Shot Task Adaptation
Text-to-LoRA (T2L) is designed for the instant adaptation of LLMs via natural language descriptions. In traditional workflows, if a developer wants an LLM to follow a specific formatting style or solve a niche mathematical problem, they must either provide many examples in the prompt or fine-tune a dedicated adapter. T2L automates this by generating a task-specific LoRA adapter from a simple text prompt.
Architecture and Training Methodologies
The T2L architecture consists of a task encoder that converts natural language descriptions into vector representations. These vectors, paired with learnable module and layer embeddings, are fed through Multi-Layer Perceptron (MLP) blocks. The output is a set of A and B low-rank matrices that are injected into the transformer layers of the base LLM.
Sakana AI explored two primary training schemes for T2L:
- Distillation-based Training: The hypernetwork is trained to mimic the behavior of existing, high-quality task-specific adapters.
- Supervised Fine-Tuning (SFT) Training: The hypernetwork is trained directly on task datasets to minimize the loss of the base model when the generated LoRA is applied.
The research findings indicate that SFT-trained T2L models exhibit superior generalization. By training on a diverse array of tasks, the hypernetwork learns to cluster related functionalities within the weight space. This allows it to generate effective adapters even for tasks it has never seen before. In empirical benchmarks, T2L achieved performance parity with traditional task-specific adapters on the GSM8K (math) and Arc-Challenge (reasoning) datasets. Most notably, it reduced adaptation costs by more than 400% compared to 3-shot ICL, as the model no longer needed to process example-heavy prompts during inference.
Doc-to-LoRA (D2L): Internalizing Knowledge Without Context
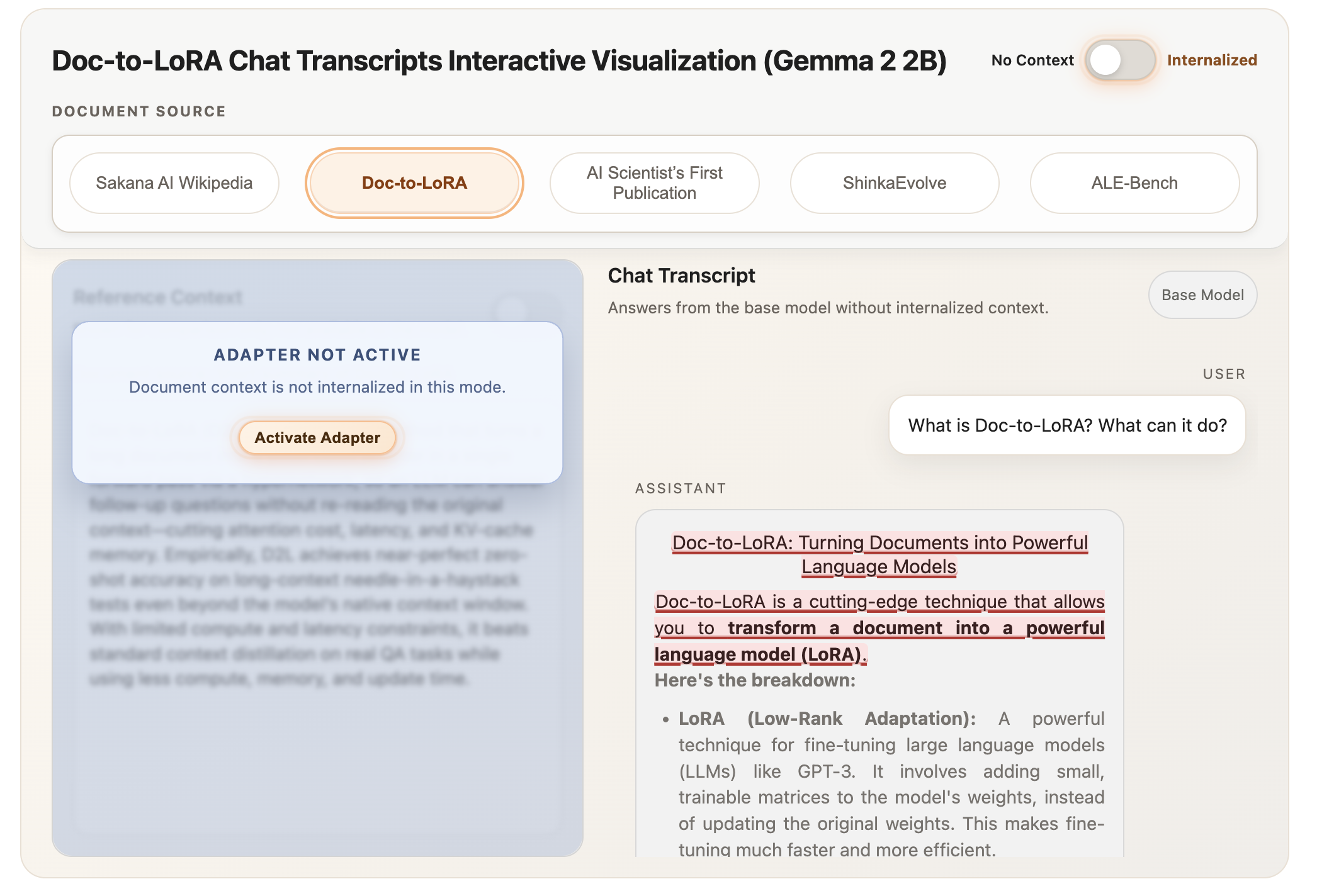
While T2L focuses on tasks, Doc-to-LoRA (D2L) addresses the challenge of long-context information retrieval. In standard systems, if a user wants to ask questions about a 50-page technical manual, that manual must stay in the LLM’s context window, occupying valuable space and slowing down response times. D2L "internalizes" the document by converting it into a LoRA adapter.
The Perceiver-Style Design and Chunking
D2L utilizes a Perceiver-style cross-attention architecture. This design allows the hypernetwork to take variable-length token activations from the base LLM and map them into a fixed-shape LoRA adapter. This is a critical innovation because it decouples the size of the input document from the complexity of the model’s internal state.
To manage documents that exceed the hypernetwork’s training capacity, Sakana AI implemented a "chunking mechanism." Long contexts are divided into contiguous segments, and the hypernetwork produces an adapter for each chunk. These are then concatenated along the rank dimension. This allows D2L to generate higher-rank LoRAs for longer inputs, effectively scaling the "brain power" applied to a document based on its length without requiring a change in the hypernetwork’s underlying architecture.
Performance in Retrieval Tasks
In the industry-standard "Needle-in-a-Haystack" (NIAH) test—where a specific piece of information is hidden within a massive document—D2L demonstrated remarkable efficiency. It maintained near-perfect retrieval accuracy even when the context length exceeded the base model’s native window by more than four times. By moving the document from the active context window into the model’s weights, D2L effectively grants the model an "infinite" memory that does not degrade inference speed.
Cross-Modal Transfer: A Breakthrough in Vision-Language Integration
One of the most unexpected and significant findings in the D2L research is its capability for cross-modal transfer. Sakana AI researchers experimented with using a Vision-Language Model (VLM) as the context encoder for D2L. They fed visual activations into the hypernetwork, which then generated LoRA weights for a text-only LLM.
The result was a text-based model that could "see." Despite the base LLM never having been trained on image data, the D2L-generated adapter allowed it to classify images from the Imagenette dataset with 75.03% accuracy. This suggests that the weight space of LLMs is flexible enough to represent information from entirely different modalities, provided a hypernetwork can correctly map those features. This opens the door for modular AI systems where a central "reasoning" model can be instantly equipped with "vision," "audio," or "sensor" modules on demand.
Chronology of Development and Context
The development of T2L and D2L sits within a broader timeline of AI efficiency research.

- 2021: Microsoft introduces LoRA, revolutionizing parameter-efficient fine-tuning.
- 2022-2023: The rise of RAG (Retrieval-Augmented Generation) as the standard for document-based AI, despite its high latency costs.
- Early 2024: Researchers begin exploring "Context Distillation" to compress prompts into model weights.
- February 2025: Sakana AI publishes the T2L and D2L papers, moving beyond simple distillation into the realm of instant, zero-shot weight generation.
Sakana AI, founded by former Google researchers including Llion Jones (one of the authors of the seminal "Attention Is All You Need" paper) and David Ha, has quickly gained a reputation for unconventional approaches to AI. Their focus on "nature-inspired" computing and model merging is reflected in T2L and D2L, which prioritize structural efficiency over raw scale.
Broader Impact and Industry Implications
The implications of Sakana AI’s hypernetworks for the AI industry are profound.
1. Enterprise Knowledge Management:
Currently, companies using RAG must maintain complex vector databases and pay for high-token-count API calls. With D2L, an enterprise could generate a 10MB LoRA file for every internal manual. When an employee asks a question, the system simply "swaps in" the relevant LoRA, allowing for instant, high-accuracy answers without the overhead of long prompts.
2. Edge Computing and Privacy:
Because these hypernetworks are lightweight, they could potentially run on edge devices (smartphones or laptops). A user could "teach" their local AI a new skill or give it access to private documents by generating a local LoRA, ensuring that sensitive data never leaves the device and that the model remains responsive without a cloud connection.
3. Dynamic Model Personalization:
T2L enables real-time personalization. As a user interacts with an AI, a hypernetwork could constantly update a "personality LoRA" or a "style LoRA" in the background, allowing the model to evolve its tone and knowledge base dynamically without a formal training cycle.
4. Reducing the Carbon Footprint of AI:
By eliminating the need for constant backpropagation for minor adaptations and reducing the computational load of processing massive KV caches, T2L and D2L contribute to more sustainable AI operations. The "one-time fee" of meta-training pays dividends in energy savings across millions of subsequent inference calls.
Conclusion: The Shift Toward Weight-Space Adaptation
Sakana AI’s introduction of T2L and D2L marks a transition from "prompt engineering" to "weight-space engineering." By proving that hypernetworks can effectively predict the necessary weight adjustments for new tasks and data, they have provided a roadmap for more agile and efficient AI systems. While standard LLMs will continue to grow in size, the tools to customize them are becoming smaller, faster, and more accessible. As the AI community moves toward 2026, the ability to "internalize" context and "generate" capabilities on the fly will likely become a standard requirement for production-grade language models.