





The Evolution of Latent Space Optimization
To understand the significance of Unified Latents, one must first look at the trajectory of generative AI over the past several years. The field has moved rapidly from Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) toward Diffusion Models, which have proven more stable and capable of producing diverse, high-quality outputs. However, training diffusion models directly on high-resolution pixel data is computationally prohibitive. This led to the rise of Latent Diffusion Models (LDMs), such as the technology powering Stable Diffusion.
LDMs operate by using an encoder to compress high-dimensional image data into a lower-dimensional "latent space." The diffusion process—adding and then removing noise—happens within this compressed space, which significantly reduces the floating-point operations (FLOPs) required for training and inference. Despite their success, LDMs face a fundamental "information density" dilemma. If the latent space is too compressed (low density), the model learns quickly, but the final reconstructed image lacks fine detail. Conversely, if the latent space preserves too much information (high density), the reconstruction is perfect, but the diffusion model struggles to learn the complex patterns within that data, requiring massive amounts of compute.
The Google DeepMind team, recognizing this friction, developed the Unified Latents (UL) framework to harmonize these conflicting requirements. By integrating the regularization of the latent space with the generative process itself, UL allows for a more fluid and efficient path from noise to high-resolution reality.
The Three Pillars of Unified Latents Architecture
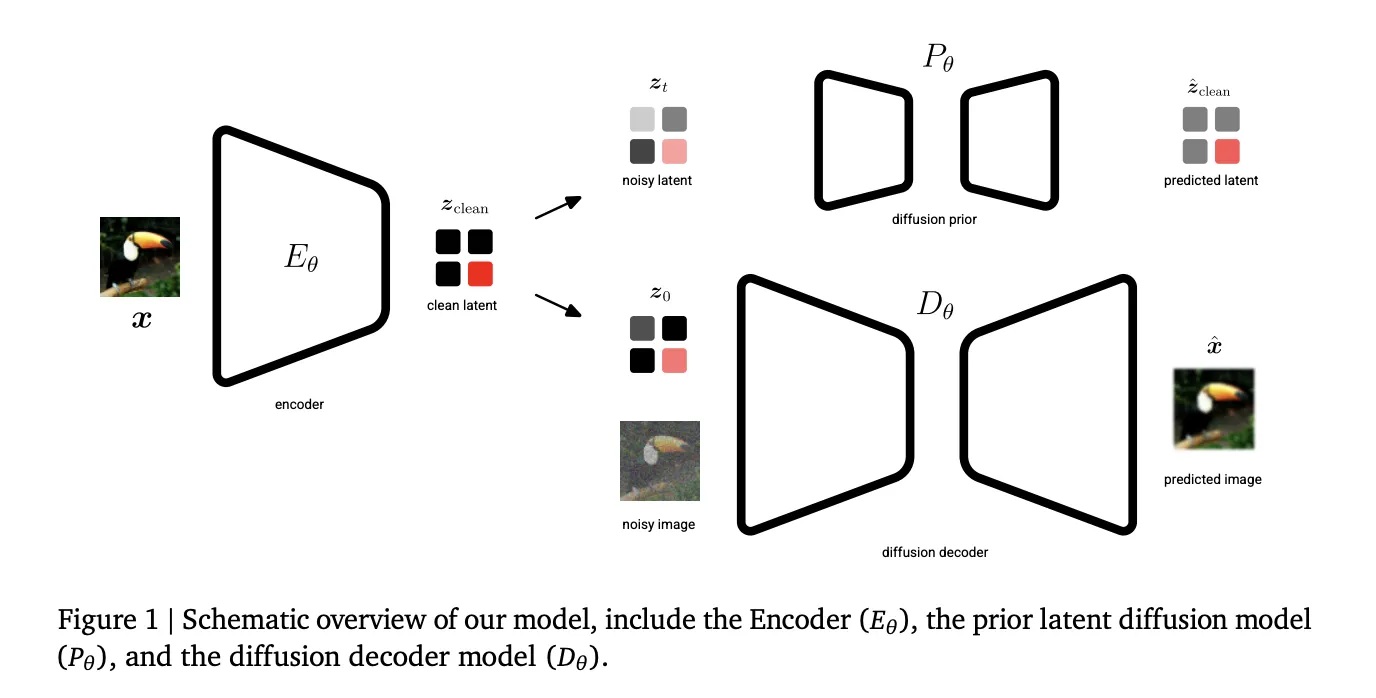
The UL framework is built upon three specific technical components that work in tandem to optimize the generative pipeline. Unlike previous models where the autoencoder and the diffusion model were often treated as separate modules trained in isolation, UL treats them as a cohesive system.
The first pillar is the Encoder. Its primary role is to map raw input data, such as pixels in an image or frames in a video, into a latent representation. In the UL framework, the encoder is designed to be highly adaptive, ensuring that the most critical features of the data are preserved even as the dimensionality is reduced.
The second pillar is the Diffusion Prior. This component serves as a regularizer for the latent space. In traditional VAEs, regularization is often handled by a simple Kullback–Leibler (KL) divergence term that pushes the latents toward a standard normal distribution. In the UL framework, the diffusion prior provides a much more sophisticated regularization. It ensures that the latent space remains "learnable" for the generative model while maintaining a tight upper bound on the latent bitrate, effectively managing how much information is stored.
The third pillar is the Diffusion Decoder. Rather than using a standard convolutional decoder to turn latents back into pixels, UL employs a diffusion-based approach for the reconstruction phase. This allows the model to "fill in the blanks" with high-frequency details that might have been lost during compression. By decoding via a diffusion model, UL can achieve near-perfect reconstruction fidelity (high PSNR) even when the latent space is highly compressed.
A Strategic Two-Stage Training Process
The implementation of Unified Latents follows a rigorous two-stage training methodology designed to maximize both the efficiency of the latent learning and the quality of the final output.
Stage 1: Joint Latent Learning and Regularization
In the initial stage, the encoder, the diffusion prior, and the diffusion decoder are trained jointly. This is a departure from standard practices where an autoencoder is typically pre-trained and then frozen. By training these components together, the UL framework ensures that the latents are optimized specifically for the diffusion process that will eventually generate them. During this stage, the encoder’s output noise is linked directly to the prior’s minimum noise level. This creates a mathematical synergy that provides a tight upper bound on the latent bitrate, ensuring that the model does not waste "modeling capacity" on irrelevant data noise.
Stage 2: Base Model Scaling and Sigmoid Weighting
The research team identified a critical limitation in Stage 1: a prior trained solely on Evidence Lower Bound (ELBO) loss tends to weight all frequencies equally. In visual data, low-frequency information (general shapes and colors) and high-frequency information (fine textures and edges) require different levels of attention.
To solve this, Stage 2 involves freezing the encoder and decoder and training a new "base model" on the learned latents. This stage utilizes a sigmoid weighting schedule, which prioritizes the learning of structural elements before refining fine details. This refinement allows for significantly larger model sizes and batch sizes, enabling the framework to scale effectively across massive datasets. The transition from Stage 1 to Stage 2 is what allows UL to achieve its state-of-the-art performance without the exponential increase in compute costs that usually accompanies such leaps in quality.
Benchmarking Success: From ImageNet to Video Generation
The technical performance of Unified Latents has been validated through rigorous benchmarking against existing state-of-the-art (SOTA) models. The results demonstrate that UL is not just a marginal improvement but a significant leap in efficiency and quality.
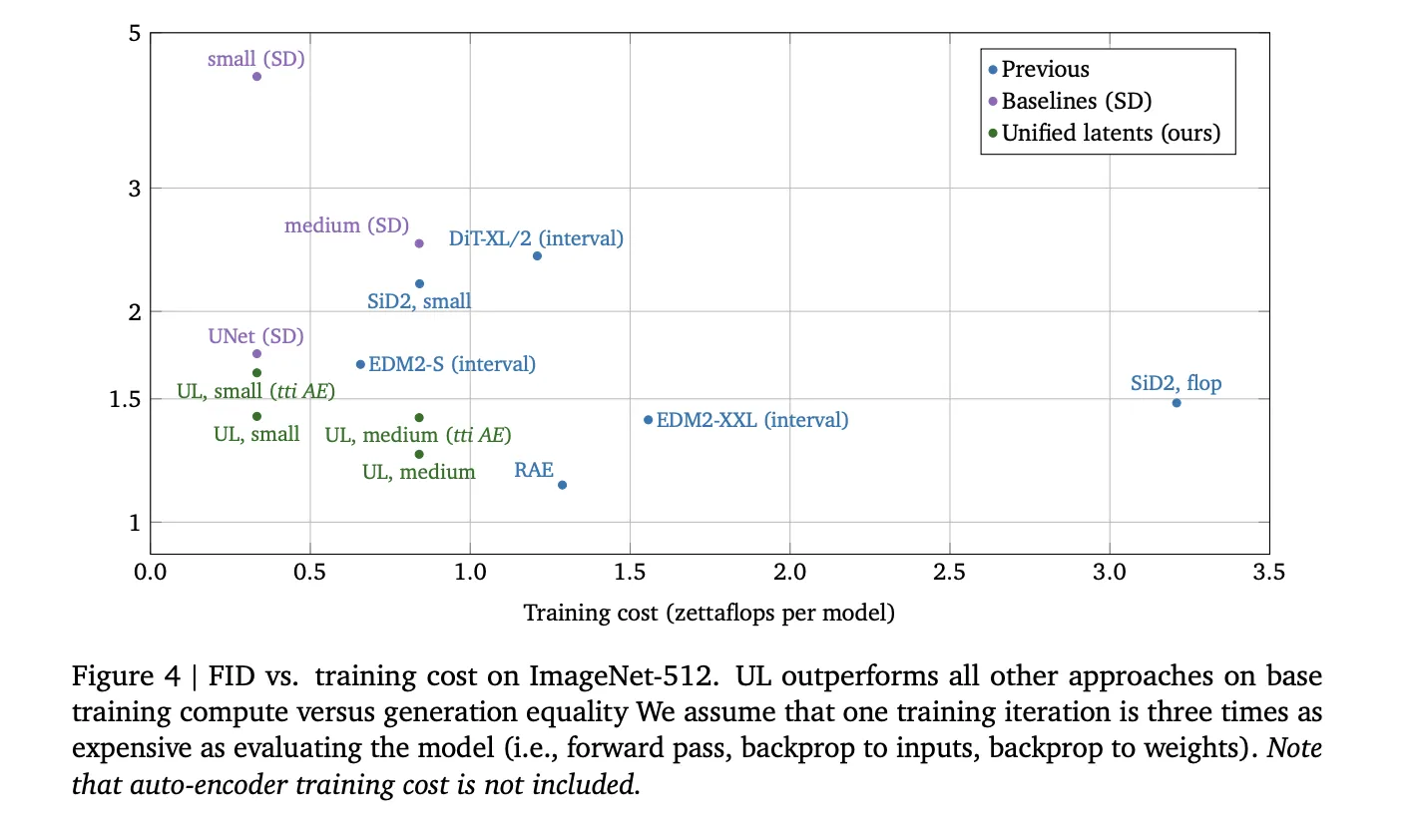
On the ImageNet-512 dataset, a standard benchmark for image synthesis, the UL framework achieved a Fréchet Inception Distance (FID) score of 1.4. To put this in perspective, UL outperformed models trained on traditional Stable Diffusion latents while using the same or even lower compute budgets. Furthermore, the model maintained a Peak Signal-to-Noise Ratio (PSNR) of up to 30.1, indicating an exceptionally high level of reconstruction fidelity.
The impact of Unified Latents is perhaps most visible in the realm of video generation. Using the Kinetics-600 dataset, the UL framework set a new SOTA benchmark. A small variant of the UL model achieved a Frechet Video Distance (FVD) of 1.7, while the medium-sized variant reached a record-breaking FVD of 1.3. These scores indicate that the video sequences generated by UL are significantly more coherent and realistic than those produced by previous architectures like DiT (Diffusion Transformer) or EDM2.
Analysis of Computational Efficiency
One of the most compelling aspects of the UL framework is its relationship between training compute (measured in FLOPs) and generation quality. In the current AI landscape, "scaling laws" dictate that more compute generally leads to better models. However, UL demonstrates that by optimizing the underlying architecture of the latent space, researchers can achieve better results with fewer resources.
By jointly regularizing the latents, the UL framework reduces the "modeling burden" on the diffusion prior. Because the latent space is more structured and less noisy than traditional latent spaces, the base model can converge faster and reach higher quality levels with less training time. This efficiency is crucial for democratizing high-end generative AI, as it reduces the barrier to entry for institutions that may not have access to the massive GPU clusters owned by the largest tech conglomerates.
Industry Implications and Future Directions
The introduction of Unified Latents by Google DeepMind is likely to trigger a ripple effect across the AI industry. For developers of creative tools, the high reconstruction fidelity of UL means that AI-generated images and videos will suffer from fewer artifacts and "hallucinations," making them more suitable for professional use in film, advertising, and design.
Furthermore, the "unified" nature of this framework suggests a path toward multi-modal models that can handle text, image, and video latents within a single, cohesive architecture. If the same regularization principles can be applied to other forms of data, we may see the emergence of "Universal Latent Models" capable of seamless cross-modal generation.
Industry experts suggest that the success of UL might prompt a re-evaluation of how "foundation models" are built. The industry has spent years focusing on scaling up transformers; DeepMind’s work suggests that equal attention must be paid to the "bottleneck" through which all data must pass: the latent space.
Conclusion
The Unified Latents framework represents a milestone in the quest for efficient, high-fidelity generative AI. By solving the fundamental trade-off between latent density and reconstruction quality, Google DeepMind has provided a blueprint for more capable and less resource-intensive models. As Stage 2 scaling continues to be explored, and as these models are integrated into broader applications, the boundary between AI-generated content and reality will likely continue to blur, driven by the mathematical precision of unified latent regularization.
The research paper, titled "Unified Latents: A Framework for Jointly Regularizing Latents with a Diffusion Prior and Decoder," serves as a comprehensive guide for the community. As the machine learning subreddit and various research forums digest these findings, the focus will undoubtedly shift toward how these "Unified Latents" can be applied to even more complex tasks, such as 3D world generation and real-time interactive simulation. For now, the benchmarks stand as a testament to the power of architectural innovation over raw computational force.












