

Microsoft has officially announced the release of Phi-4-reasoning-vision-15B, a 15 billion parameter open-weight multimodal reasoning model engineered to bridge the gap between high-fidelity visual perception and complex logical deduction. This latest addition to the Phi family represents a strategic pivot toward "compact" AI—models that prioritize computational efficiency and data quality over the brute-force scaling of parameters. Designed specifically for tasks involving scientific reasoning, mathematical problem-solving, and the interpretation of graphical user interfaces (GUIs), the model is now available for developers and researchers seeking a high-performance, open-weight alternative for multimodal applications.
The release marks a significant milestone in Microsoft’s ongoing effort to democratize advanced AI capabilities through the Phi series. By providing open-weight access, Microsoft allows the global research community to inspect, fine-tune, and deploy the model in diverse environments, ranging from cloud-based infrastructure to high-end edge devices. The Phi-4-reasoning-vision-15B model is built on the premise that a model does not need trillions of parameters to exhibit sophisticated reasoning if the underlying training data and architecture are meticulously optimized.
The Evolution of the Phi Series: A Chronological Context
The journey toward Phi-4-reasoning-vision-15B began several years ago with Microsoft’s "Textbooks Are All You Need" philosophy. To understand the significance of this new release, it is essential to trace the chronology of the Phi lineage:
- Phi-1 and Phi-1.5 (2023): Microsoft initially shocked the AI industry by demonstrating that a small model (1.3 billion parameters) could outperform much larger counterparts in coding and logic tasks by training on high-quality, synthetic "textbook-style" data.
- Phi-2 (Late 2023): A 2.7 billion parameter model that expanded the series’ capabilities into general reasoning, proving that small language models (SLMs) could compete with models ten times their size.
- Phi-3 (2024): This generation introduced multimodal variants (Phi-3-Vision) and explored different sizes (Mini, Small, Medium), integrating more robust training techniques and longer context windows.
- Phi-4 (Early 2025): The base Phi-4 model introduced enhanced reasoning capabilities. The subsequent release of the "Reasoning-Vision" variant marks the culmination of these efforts, integrating advanced vision encoders with the latest reasoning-focused language backbones.
This progression reflects a broader industry trend toward "agentic" AI—models that can not only understand text but can also "see" a screen and reason through the steps required to complete a task.

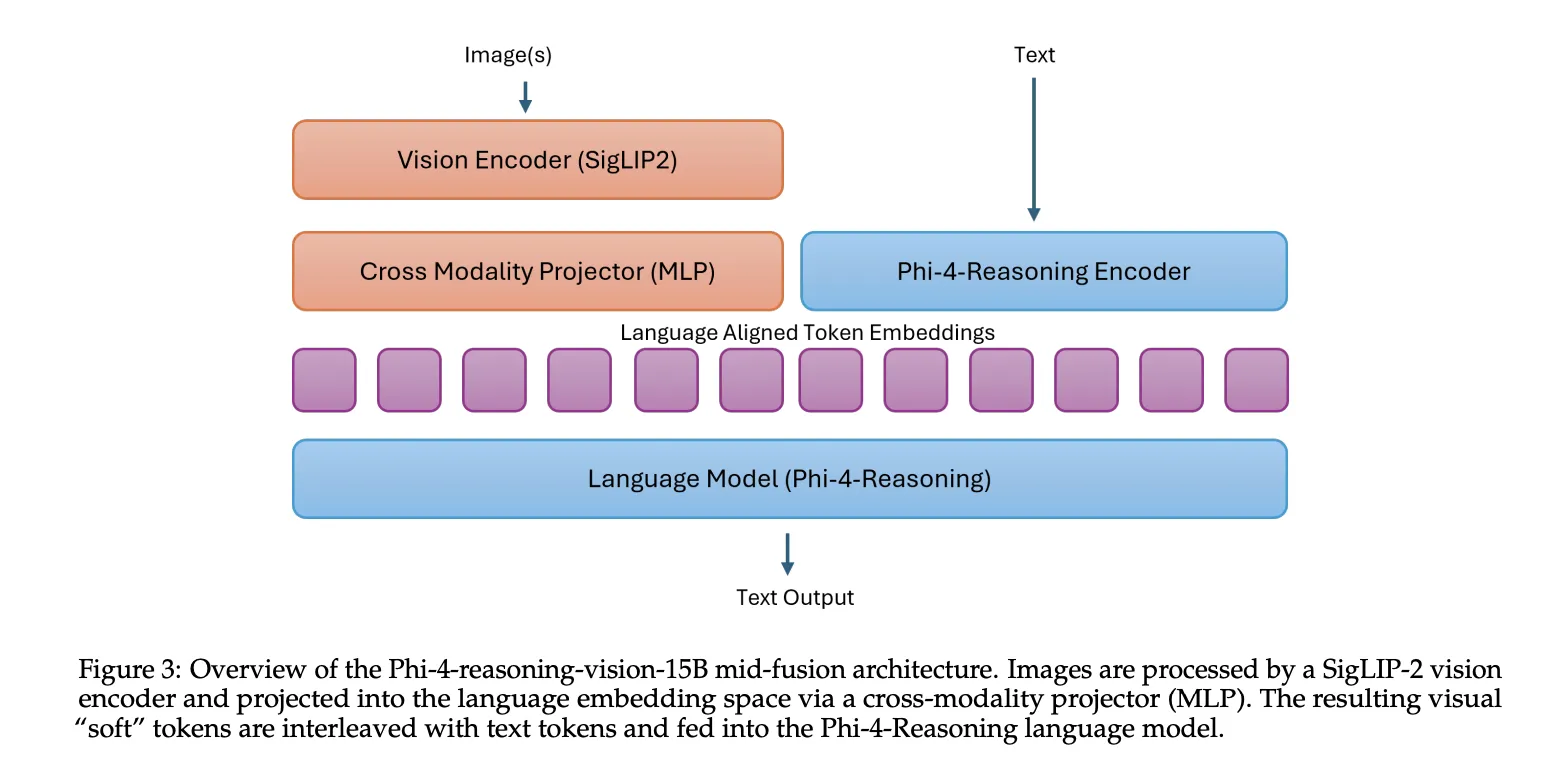
Architectural Innovation: The Mid-Fusion Approach
At the heart of Phi-4-reasoning-vision-15B is a sophisticated "mid-fusion" architecture. In the landscape of multimodal AI, developers typically choose between "early-fusion" (where visual and text data are integrated from the start) and "late-fusion" (where separate models process data before a final layer combines them). Microsoft’s mid-fusion design serves as a pragmatic middle ground.
The model utilizes the SigLIP-2 vision encoder to convert images into visual tokens. These tokens are then projected into the language model’s embedding space, where they are processed by the Phi-4-Reasoning backbone. This setup allows the model to maintain a deep understanding of cross-modal relationships while significantly reducing the computational overhead associated with more complex early-fusion designs. By leveraging the SigLIP-2 encoder, the model achieves a more nuanced understanding of spatial relationships within an image, which is critical for tasks like reading a complex chart or identifying a specific button on a smartphone screen.
Data Efficiency: Quality Over Quantity
One of the most striking aspects of the Phi-4-reasoning-vision-15B release is its training efficiency. While contemporary competitors like Qwen 2.5 VL, Kimi-VL, and Gemma 3 often rely on training sets exceeding 1 trillion tokens, Microsoft’s model was developed using a much leaner dataset.
The training regimen for this model involved:
- 400 Billion Tokens: The original Phi-4 base model training.
- 16 Billion Tokens: Focused reasoning training for the Phi-4-Reasoning backbone.
- 200 Billion Multimodal Tokens: Final integration training for the vision-language capabilities.
By focusing on a total multimodal mixture of approximately 200 billion tokens, Microsoft has demonstrated that targeted, high-quality data can compensate for a smaller parameter count. This "lean" approach makes the model particularly attractive for organizations that need to fine-tune AI on proprietary data without the astronomical costs associated with larger foundational models.

Perception as a Prerequisite for Reasoning
A core thesis of the Microsoft research team, as detailed in their technical report, is that "perception fails before reasoning does." In many failed multimodal AI interactions, the model does not lack the logic to solve a problem; rather, it fails to "see" the data correctly. If an AI cannot distinguish a "plus" sign from a "division" sign in a low-resolution image of a math problem, its reasoning capabilities are irrelevant.
To solve this, Phi-4-reasoning-vision-15B employs a dynamic resolution vision encoder. This system can generate up to 3,600 visual tokens for a single image, allowing it to maintain high fidelity even when analyzing dense documents, intricate scientific diagrams, or high-resolution screenshots. This high-resolution capability is the engine behind the model’s superior performance in GUI grounding—the ability to pinpoint and understand interactive elements within a software interface.
Adaptive Logic: The "Think" vs. "Nothink" Strategy
A common criticism of reasoning-heavy models is their tendency to over-analyze simple tasks, leading to unnecessary latency. Microsoft addresses this through a "mixed reasoning" training strategy. The model is trained to distinguish between tasks that require a "Chain of Thought" (CoT) and those that require a direct response.
- Reasoning Mode: For complex math or science problems, the model generates internal reasoning traces encapsulated in
<think>...</think>tags. - Non-Reasoning Mode: For simple tasks like OCR (Optical Character Recognition), captioning, or basic image tagging, the model uses a
<nothink>tag and provides a direct answer.
Approximately 20% of the training data consisted of reasoning samples. This hybrid approach allows the model to be "fast where possible and smart where necessary." While the model learns to switch modes implicitly, Microsoft has enabled a manual override feature, allowing users to force a specific mode through prompting—a feature that provides developers with greater control over the end-user experience.
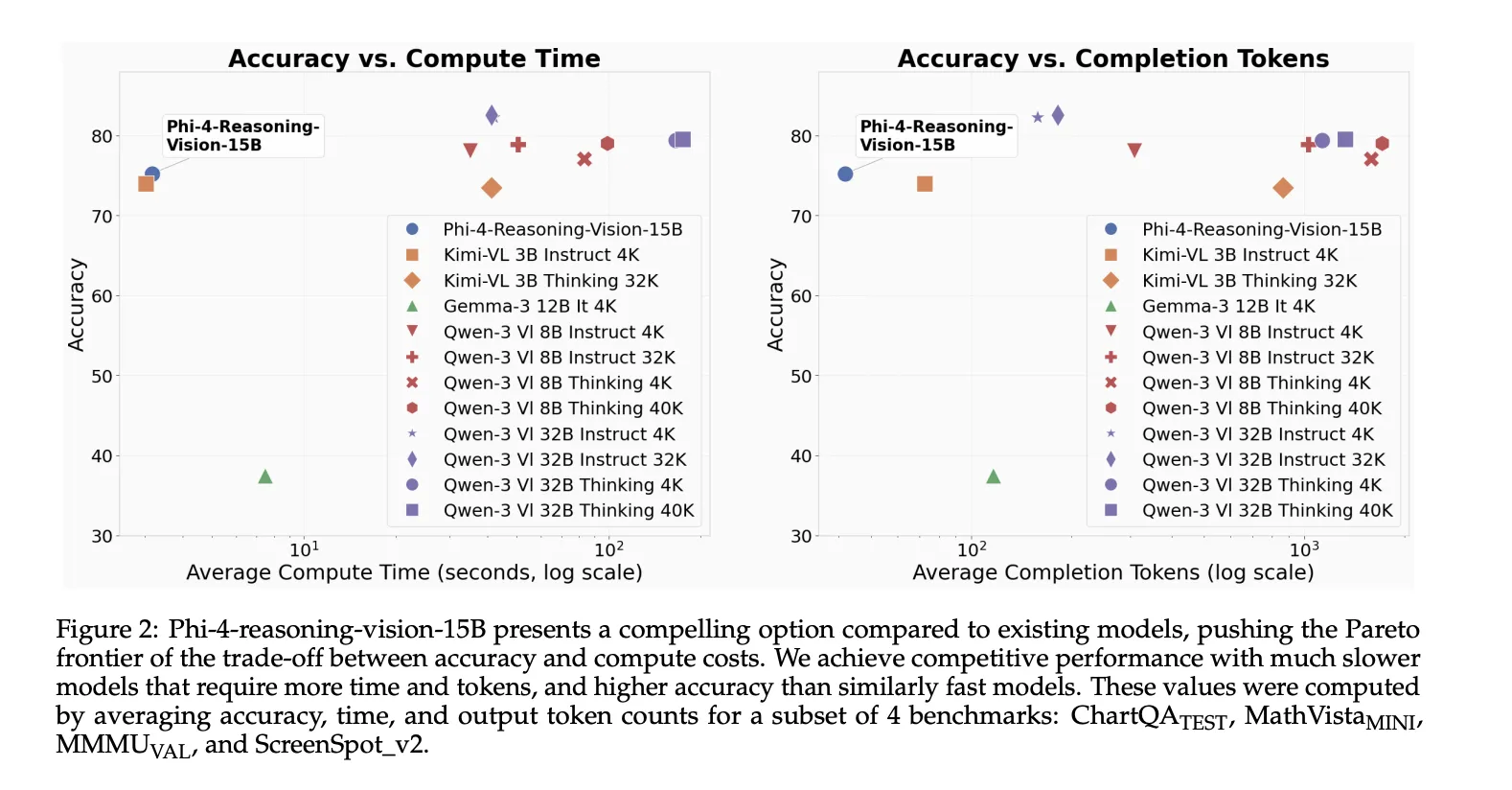
Performance Metrics and Benchmarking
Microsoft’s internal testing, conducted using the Eureka ML Insights and VLMEvalKit frameworks, suggests that Phi-4-reasoning-vision-15B is a formidable competitor in the mid-sized model category. The model’s performance across various specialized benchmarks is as follows:
- ScreenSpot v2 (88.2): Highlighting its dominance in GUI element localization and interface understanding.
- AI2D Test (84.8): Demonstrating strong performance in interpreting science diagrams.
- ChartQA Test (83.3): Proving its ability to extract and reason over data presented in visual charts.
- MathVista MINI (75.2): Showing a high aptitude for visual mathematical reasoning.
- OCRBench (76.0): Confirming its reliability in text extraction from images.
- MMMU VAL (54.3): Indicating solid performance in multi-discipline college-level tasks requiring visual input.
Microsoft has clarified that these figures are intended as comparison points rather than definitive leaderboard claims, emphasizing the model’s balanced performance across diverse domains rather than a single-minded focus on one metric.
Implications for the AI Ecosystem and "Computer Use" Agents
The release of Phi-4-reasoning-vision-15B has profound implications for the development of "Computer Use" agents—AI systems that can navigate operating systems and web browsers much like a human does. Because the model excels at interpreting screen content and localizing GUI elements, it serves as an ideal "brain" for automation tools that need to interact with legacy software or mobile apps that do not have traditional APIs.
Furthermore, the open-weight nature of the model is a boon for the open-source community. It provides a blueprint for how to build efficient multimodal systems without the need for massive, secretive datasets. Developers in the scientific and medical fields, in particular, may find the model’s ability to reason over diagrams and handwritten equations invaluable for automating the analysis of research papers and lab notes.
Future Outlook and Official Availability
Microsoft has made the model weights available on Hugging Face and the code repository on GitHub, signaling a commitment to transparency and collaborative development. As the AI industry continues to debate the merits of "scaling laws" versus "data quality," the Phi-4-reasoning-vision-15B stands as a compelling argument for the latter.
The move is likely to prompt responses from competitors such as Google and Meta, who are also racing to release more efficient, multimodal versions of their respective models (Gemma and Llama). For now, Microsoft’s latest release sets a high bar for what a 15-billion-parameter model can achieve, particularly in the niche but critical areas of scientific reasoning and digital interface navigation.
In summary, Phi-4-reasoning-vision-15B is not just another incremental update; it is a specialized tool designed for the next generation of AI agents. By solving the "perception first" problem and offering a flexible reasoning framework, Microsoft is providing the building blocks for AI that can truly understand and interact with the visual world of human computing.