By integrating a 0.4B CogViT visual encoder with a 0.5B GLM language decoder through a lightweight cross-modal connector, the research team has developed a system that balances high-performance recognition with the low-latency requirements of edge deployment and large-scale production environments. This release marks a significant pivot in the industry, moving away from "brute force" scaling toward architectural efficiency and task-specific optimization.
The Engineering Hurdle: Why Traditional OCR Falls Short
For decades, OCR was synonymous with simple text transcription—converting scanned images of typewritten text into machine-readable strings. However, as digital transformation has accelerated across the legal, financial, and medical sectors, the definition of a "document" has evolved. Modern documents are rarely just "clean demo images"; they are dense repositories of structured data featuring multi-column layouts, overlapping seals, complex chemical or mathematical notation, and embedded code blocks.
Traditional OCR engines, while proficient at line-by-line text extraction, struggle with spatial reasoning. They often lose the hierarchical context of a document, failing to distinguish between a header, a footer, and a table cell. Conversely, general-purpose Large Multimodal Models (LMMs), while capable of understanding these structures, are often prohibitively expensive to run for high-volume document processing. The "resource bonfire" of running a 70B or 100B parameter model just to extract data from an invoice is economically unfeasible for most enterprises. GLM-OCR is positioned as the surgical alternative—a model small enough for efficient deployment but specialized enough to outperform much larger generalist systems in the specific domain of document parsing.
Architectural Innovation: Multi-Token Prediction and Hybrid Decoding
At the heart of GLM-OCR’s efficiency is a technical departure from standard autoregressive decoding. Most language models predict one token at a time, a process that is inherently sequential and often slow. For OCR tasks, where the output is frequently deterministic and highly structured (such as a predictable JSON schema or a Markdown table), the one-token-at-a-time approach is a bottleneck.
To solve this, the Zhipu AI and Tsinghua team implemented Multi-Token Prediction (MTP). During the training phase, the model is taught to predict up to 10 tokens simultaneously per step. In practical inference scenarios, this translates to an average of 5.2 tokens generated per decoding step. The result is a documented 50% improvement in throughput without a corresponding spike in memory consumption. This is achieved through a clever parameter-sharing scheme across draft models, ensuring that the model remains "compact" in terms of its hardware footprint while performing like a much larger engine in terms of speed.
The Two-Stage Pipeline: A Divide and Conquer Strategy
Rather than treating a document page as a single, flat image to be read from top-left to bottom-right, GLM-OCR utilizes a sophisticated two-stage pipeline. This approach acknowledges that spatial awareness is just as important as character recognition.
- Layout Analysis (The Macro View): The system first employs PP-DocLayout-V3, a specialized tool for detecting structured regions on a page. This stage identifies where tables begin, where formulas are located, and where text blocks are separated.
- Parallel Region Recognition (The Micro View): Once the layout is mapped, GLM-OCR performs parallel recognition over these specific areas. This "divide and conquer" strategy prevents the model from getting lost in complex layouts and allows it to maintain high accuracy on documents with non-linear reading orders, such as academic papers with sidebars or financial reports with multi-layered tables.
This structural separation also allows the model to switch between different output modes. For document parsing, it generates Markdown or JSON that reflects the visual hierarchy of the page. For Key Information Extraction (KIE), the model can be prompted to ignore the bulk of the text and focus solely on specific fields—such as "Total Amount Due" or "Patient ID"—generating a clean JSON output directly from the full document image.
A Chronology of Development: The Four-Stage Training Process
The robustness of GLM-OCR is the result of a meticulously planned four-stage training regimen designed to build the model’s capabilities incrementally.

- Stage 1: Vision Foundation: The initial phase focused on training the 0.4B CogViT visual encoder. Using vast datasets of image-text pairs and grounding data, the encoder was taught to recognize basic shapes, textures, and the spatial relationships between visual elements.
- Stage 2: Multimodal Integration and MTP: In this stage, the visual encoder was linked to the language decoder. The team introduced multimodal pretraining, combining traditional VQA (Visual Question Answering) with document parsing tasks. Crucially, the Multi-Token Prediction (MTP) objective was introduced here, teaching the model to think in "blocks" of text rather than individual characters.
- Stage 3: Supervised Fine-Tuning (SFT): The model was then subjected to rigorous fine-tuning on OCR-specific datasets. This included high-resolution transcriptions of mathematical formulas, table structure recovery, and the recognition of "noisy" documents containing seals, stamps, and handwriting.
- Stage 4: Reinforcement Learning via GRPO: The final stage utilized Group Relative Policy Optimization (GRPO) to align the model’s outputs with human expectations of accuracy. Unlike general RLHF (Reinforcement Learning from Human Feedback), the rewards here were objective and task-specific. For text, the model was rewarded based on Normalized Edit Distance; for formulas, the CDM score was used; and for tables, the TEDS (Tree Edit Distance-based Similarity) score served as the benchmark.
Benchmark Performance and Comparative Data
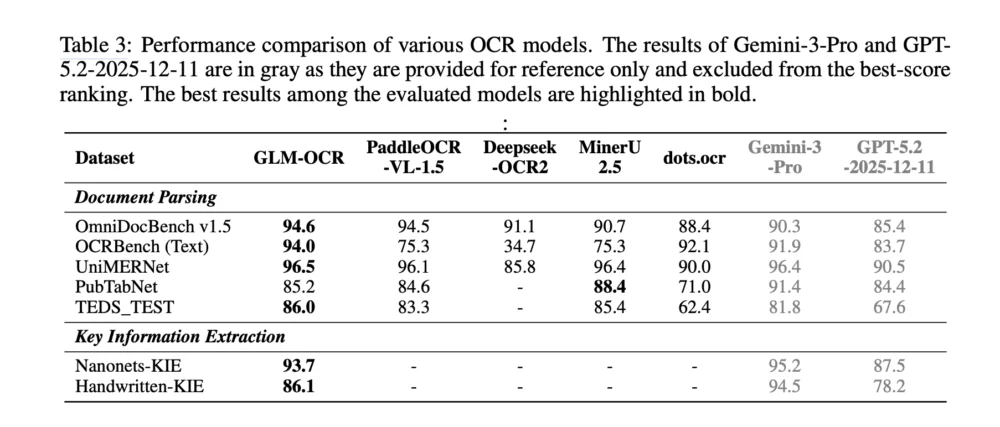
The research team released comprehensive benchmark results that place GLM-OCR at the top of its weight class. In the specialized OmniDocBench v1.5, the model achieved a score of 94.6, signaling its proficiency in handling diverse document types. It also recorded a 94.0 on OCRBench (Text) and a 96.5 on UniMERNet, the latter highlighting its exceptional ability to transcribe mathematical notation.
However, the team provided an honest assessment of the competitive landscape. While GLM-OCR outperformed many open-source models, it was noted that frontier models like Gemini-3-Pro and GPT-5.2 (2025-12-11 versions) still hold a lead in certain high-complexity tasks, particularly in Key Information Extraction from extremely "noisy" handwritten documents. Furthermore, in the PubTabNet benchmark for table recognition, GLM-OCR’s score of 85.2 was slightly edged out by MinerU 2.5’s 88.4.
These results suggest that while GLM-OCR is perhaps the most efficient model for its size, the ceiling for document understanding is still being pushed by massive-scale proprietary models. Nonetheless, for the vast majority of enterprise use cases, the performance gap is marginal compared to the massive savings in cost and latency.
Deployment and Economic Implications
One of the most compelling aspects of the GLM-OCR announcement is its immediate readiness for production. The model supports popular inference frameworks including vLLM, SGLang, and Ollama, and it can be easily fine-tuned for specific niche industries using LLaMA-Factory.
The economic argument for GLM-OCR is particularly strong. Zhipu AI has introduced a Model-as-a-Service (MaaS) API priced at approximately 0.2 RMB per million tokens. To put this in perspective, for a standard company processing thousands of scanned invoices or legal contracts daily, the cost of using GLM-OCR is a fraction of the cost associated with larger multimodal APIs. The reported throughput of 1.86 PDF pages per second ensures that even massive backlogs of archived documents can be digitized in a matter of hours rather than weeks.
Broader Impact and Future Outlook
The release of GLM-OCR signals a broader trend in the AI industry: the move toward "Small Multimodal Models" (SMMs). While the "bigger is better" era of AI development yielded impressive general-purpose assistants, the next phase of AI adoption will likely be driven by highly efficient, task-specific models that can run on local servers or even high-end mobile devices.
By solving the "hard engineering problem" of OCR through a combination of layout-aware pipelines and multi-token prediction, Zhipu AI and Tsinghua University have provided a blueprint for how AI can be integrated into the boring but essential plumbing of global commerce and administration. As these models continue to shrink in size while growing in capability, the barrier to high-accuracy automated document processing will virtually disappear, enabling a new level of data liquidity in traditionally paper-heavy industries.
The research team has made the paper, code repository, and model weights publicly available, inviting the global developer community to build upon their foundation. As organizations move to adopt these compact models, the focus will likely shift from basic recognition to higher-level reasoning—moving from simply "reading" the document to truly "understanding" the implications of the data contained within.