




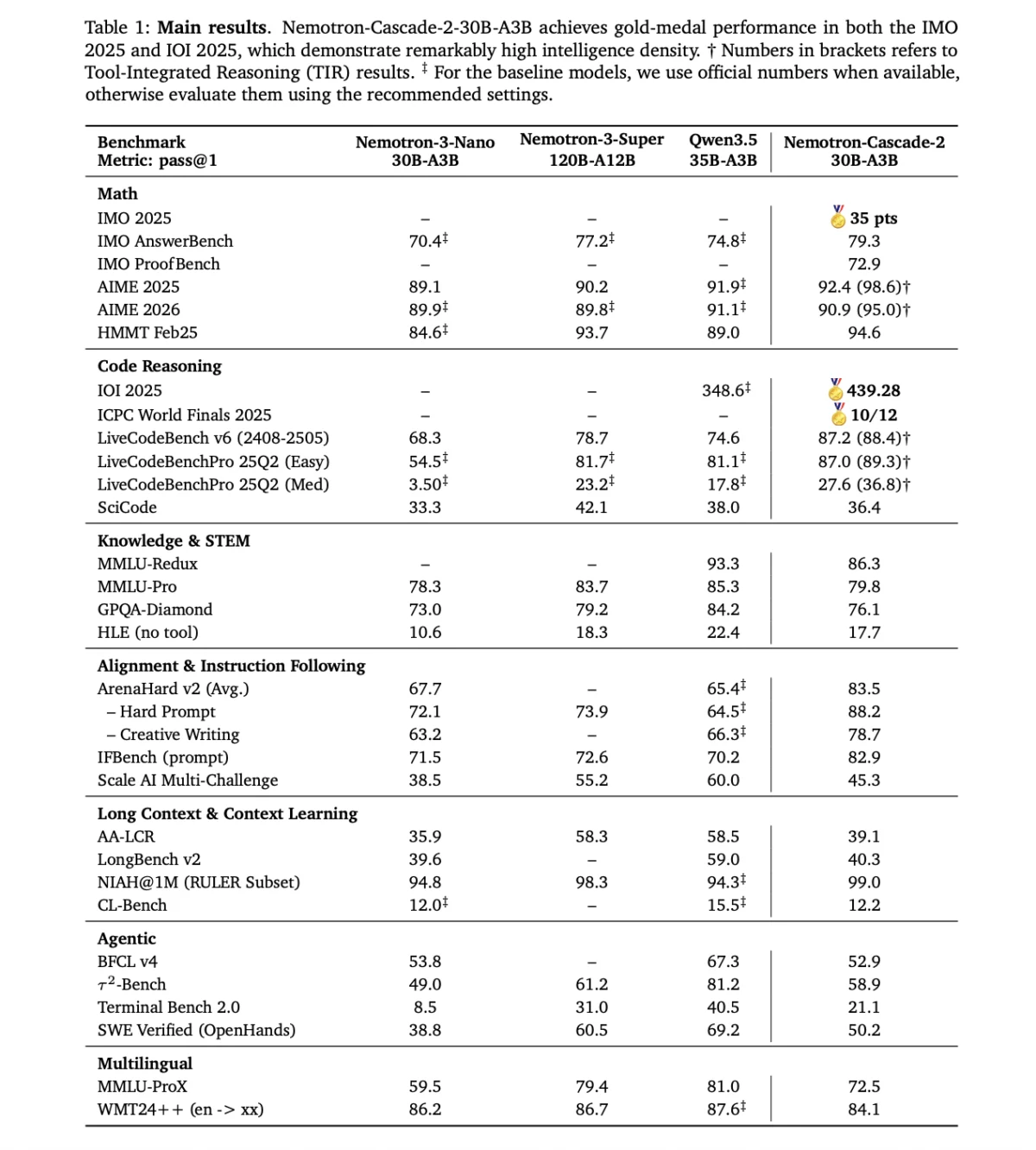
NVIDIA has officially announced the launch of Nemotron-Cascade 2, a groundbreaking open-weight large language model (LLM) designed to challenge the performance of frontier-scale models while maintaining a significantly smaller computational footprint. Utilizing a 30-billion parameter Mixture-of-Experts (MoE) architecture, the model activates only 3 billion parameters during any single inference pass. This strategic design emphasizes "intelligence density," a metric NVIDIA defines as the ratio of reasoning capability to active parameter count. By achieving Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, Nemotron-Cascade 2 establishes a new benchmark for efficiency in the open-source AI ecosystem.
The release marks a significant milestone in NVIDIA’s broader strategy to democratize high-level reasoning capabilities. Traditionally, the level of mathematical and logical proficiency demonstrated by Nemotron-Cascade 2 was reserved for models with hundreds of billions of parameters, often gated behind proprietary APIs. By releasing this model with open weights, NVIDIA provides developers and researchers with a tool capable of sophisticated problem-solving that can be deployed on consumer-grade or mid-range enterprise hardware.
The Evolution of Intelligence Density
The concept of intelligence density represents a shift in AI development priorities. For much of the last three years, the industry focused on scaling—simply adding more parameters and data to achieve better results. However, the release of Nemotron-Cascade 2 suggests a pivot toward architectural refinement and training efficiency. With only 3 billion active parameters, the model matches or exceeds the performance of much larger predecessors, such as the Nemotron-3-Super-120B-A12B, in specific reasoning-intensive domains.
This efficiency is largely attributed to the Mixture-of-Experts (MoE) framework. In a standard dense model, every parameter is used for every token generated. In an MoE model, the workload is distributed across specialized "experts." For any given input, a gating mechanism selects the most relevant experts to handle the task. This allows the model to possess a vast "knowledge base" of 30 billion parameters while only "paying" the computational cost of 3 billion during execution. The result is a model that is fast enough for real-time applications but smart enough for complex mathematical proofs.
Technical Architecture and Post-Training Innovations
The development of Nemotron-Cascade 2 began with the Nemotron-3-Nano-30B-A3B-Base model. To transform this base into a reasoning powerhouse, the NVIDIA research team employed a sophisticated multi-stage post-training pipeline. This process was divided into Supervised Fine-Tuning (SFT) and a novel reinforcement learning approach known as Cascade RL.

Supervised Fine-Tuning (SFT)
During the SFT phase, the model was exposed to a meticulously curated dataset. A key technical highlight of this stage was the packing of samples into sequences of up to 256,000 tokens. This long-context capability is essential for modern AI applications, particularly in software engineering and document analysis. The dataset included:
- High-Quality Reasoning Chains: Step-by-step solutions to complex problems.
- Diverse Instruction Sets: Data designed to improve the model’s ability to follow nuanced human commands.
- Specialized Coding Data: Extensive repositories of code and documentation to bolster software engineering capabilities.
Cascade Reinforcement Learning
Following SFT, NVIDIA applied Cascade RL, a sequential, domain-specific training methodology. One of the primary challenges in training multi-talented AI models is "catastrophic forgetting," where learning a new skill (like advanced calculus) causes the model to lose proficiency in an old one (like creative writing).
Cascade RL mitigates this by applying RL in stages—Instruction-Following (IF-RL), Multi-domain RL, RLHF (Reinforcement Learning from Human Feedback), and specialized Code and Software Engineering (SWE) RL. This allows researchers to tailor hyperparameters for specific domains without destabilizing the model’s overall performance.
Breakthrough via Multi-Domain On-Policy Distillation (MOPD)
Perhaps the most significant technical contribution of Nemotron-Cascade 2 is the integration of Multi-Domain On-Policy Distillation (MOPD). In this process, the model learns from "teacher" models that were also derived from the same SFT initialization but specialized in specific areas.
The research team found that MOPD is substantially more sample-efficient than sequence-level reward algorithms such as Group Relative Policy Optimization (GRPO). For instance, in the American Invitational Mathematics Examination (AIME25) benchmarks, MOPD allowed the model to reach a teacher-level performance score of 92.0 within just 30 training steps. In comparison, GRPO achieved a lower score of 91.0 after the same number of steps. This efficiency suggests that MOPD provides a "denser" learning signal, allowing the model to internalize complex logic faster than traditional methods.
Benchmarks and Competitive Analysis
NVIDIA’s internal testing places Nemotron-Cascade 2 at the top of its weight class. When compared to the Qwen3.5-35B-A3B (released in February 2026) and the larger Nemotron-3-Super-120B-A12B, the Cascade 2 model shows targeted superiority:
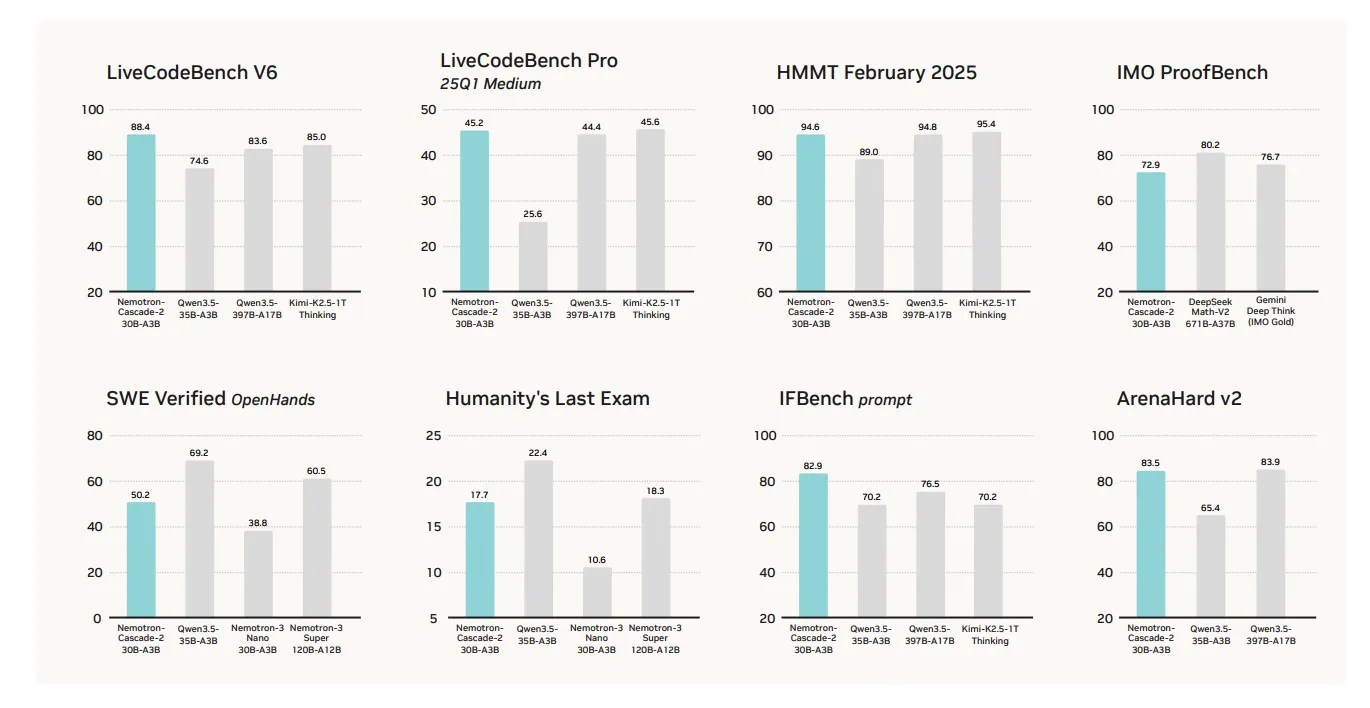
- Mathematical Reasoning: The model achieved Gold Medal-level status in the 2025 IMO, a feat previously thought impossible for a 30B-scale model.
- Coding and Informatics: In the IOI and ICPC World Finals benchmarks, the model demonstrated an ability to synthesize complex algorithms and debug intricate codebases with high accuracy.
- Instruction Following: The model scores exceptionally high on alignment benchmarks, ensuring it remains helpful and harmless while strictly adhering to user-defined constraints.
However, NVIDIA is transparent about the model’s limitations. It is not presented as a "blanket win" across all possible benchmarks. While it dominates in reasoning, math, and coding, it may perform similarly to other models in creative writing or general knowledge retrieval where raw parameter count often correlates more strongly with performance.
Agentic Capabilities and Tool Use
Beyond its raw reasoning power, Nemotron-Cascade 2 is designed for "agentic" interaction. This refers to the model’s ability to act as an autonomous agent that can use external tools to complete tasks. The model supports two primary operating modes:
- Chat Mode: Optimized for natural, multi-turn dialogue with a focus on reasoning and explanation.
- Agentic Mode: Utilizes a structured tool-calling protocol.
In Agentic Mode, the model uses a specialized system prompt that includes <tools> tags. When a user asks a question that requires external data or computation—such as "What is the current stock price of NVIDIA?" or "Run this Python script"—the model generates a tool call wrapped in <tool_call> tags. This structured output allows the software environment to execute the command and return the result to the model, which then synthesizes the final answer. This capability is critical for the next generation of AI assistants that must interact with APIs, databases, and file systems.
Chronology of the Release
The release of Nemotron-Cascade 2 follows a rapid succession of developments in the AI sector:
- Late 2025: NVIDIA releases the first Nemotron-Cascade, proving that MoE architectures could handle reasoning tasks effectively.
- February 2026: Alibaba releases Qwen3.5-35B-A3B, setting a high bar for mid-sized open-weight models.
- March 2026: NVIDIA responds with Nemotron-Cascade 2, introducing MOPD and achieving IMO Gold Medal status.
This timeline highlights the intense competition between American and Chinese AI labs to produce the most efficient "small-yet-mighty" models.
Industry Implications and Future Outlook
The launch of Nemotron-Cascade 2 has significant implications for the AI industry and the broader tech landscape. By providing a model that is both open-weight and highly capable, NVIDIA is shifting the balance of power away from centralized API providers.
1. Enterprise Cost Reduction:
For businesses, the 3B active parameter count means that high-level reasoning can be integrated into applications at a fraction of the previous inference cost. Companies can host these models on-premises, ensuring data privacy while maintaining performance that rivals top-tier proprietary models.
2. The Rise of Local Reasoning:
With the right optimization, a 30B MoE model can run on high-end consumer GPUs. This brings "Gold Medal-level" math and coding assistance to the local machines of individual developers and students, reducing reliance on internet connectivity and subscription-based services.
3. Advancements in Autonomous Engineering:
The model’s success in the IOI and ICPC benchmarks suggests it will be a cornerstone for autonomous software engineering agents. These agents can potentially write, test, and deploy code with minimal human intervention, accelerating the pace of digital innovation.
4. A New Standard for Open Science:
By publishing the research paper and the weights on platforms like Hugging Face, NVIDIA continues to support the open-science movement. This transparency allows the global research community to dissect the MOPD and Cascade RL techniques, likely leading to further innovations in model training efficiency.
In conclusion, Nemotron-Cascade 2 is more than just a model release; it is a proof of concept for the future of artificial intelligence. It demonstrates that the path to "frontier" performance does not always require more hardware and more electricity—sometimes, it simply requires more "intelligent" training. As the industry moves forward, the focus will likely remain on this "intelligence density," as developers seek to pack more reasoning power into smaller, faster, and more accessible packages.












