




As the deployment of Large Language Models (LLMs) transitions from experimental research to global industrial scale, the primary bottleneck hindering efficiency has shifted from raw computational power to GPU memory management. While early optimization efforts focused on accelerating matrix multiplications and reducing latency for individual requests, the industry now faces a critical challenge in throughput: how to serve hundreds or thousands of concurrent users without exhausting the limited High Bandwidth Memory (HBM) available on modern accelerators. The emergence of Paged Attention, a memory management technique inspired by classic operating system design, has fundamentally altered the landscape of AI inference. By treating the Key-Value (KV) cache as a series of non-contiguous virtual pages rather than large static blocks, Paged Attention allows for nearly 100% memory utilization, significantly increasing the number of requests a single GPU can handle.
The KV Cache and the Memory Bottleneck
To understand the necessity of Paged Attention, one must first examine the mechanics of autoregressive decoding. When an LLM generates text, it does so one token at a time. To produce each new token, the model must attend to all previously generated tokens. Recomputing the hidden states for every preceding token at every step would be computationally prohibitive. To solve this, systems implement a "KV cache," which stores the Key and Value tensors for all previous tokens in the sequence.
However, this cache is remarkably large. In a standard Transformer architecture, such as a model with 32 layers, 32 attention heads, and a head dimension of 128, each token requires a specific amount of memory. Using 16-bit floating-point precision (fp16), the memory footprint is calculated as:
$2 text (Key and Value) times 32 text (layers) times 32 text (heads) times 128 text (dimension) times 2 text (bytes per fp16 value)$.
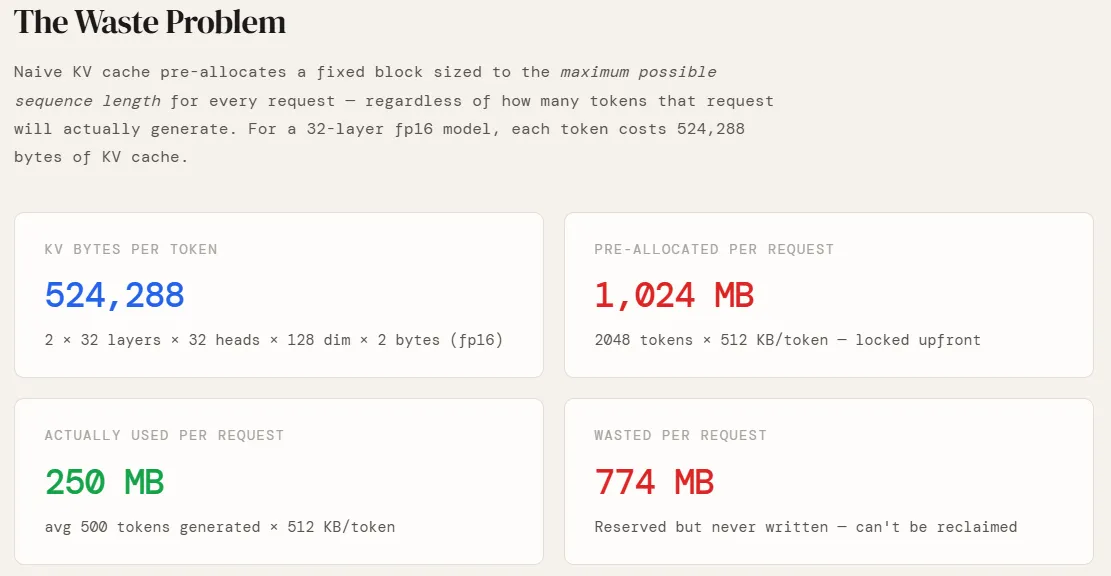
This results in 524,288 bytes, or exactly 0.5 MB, per token. For a single request with a maximum sequence length of 2,048 tokens, the system must be prepared to store 1,024 MB of data.
The Inefficiency of Naive Allocation
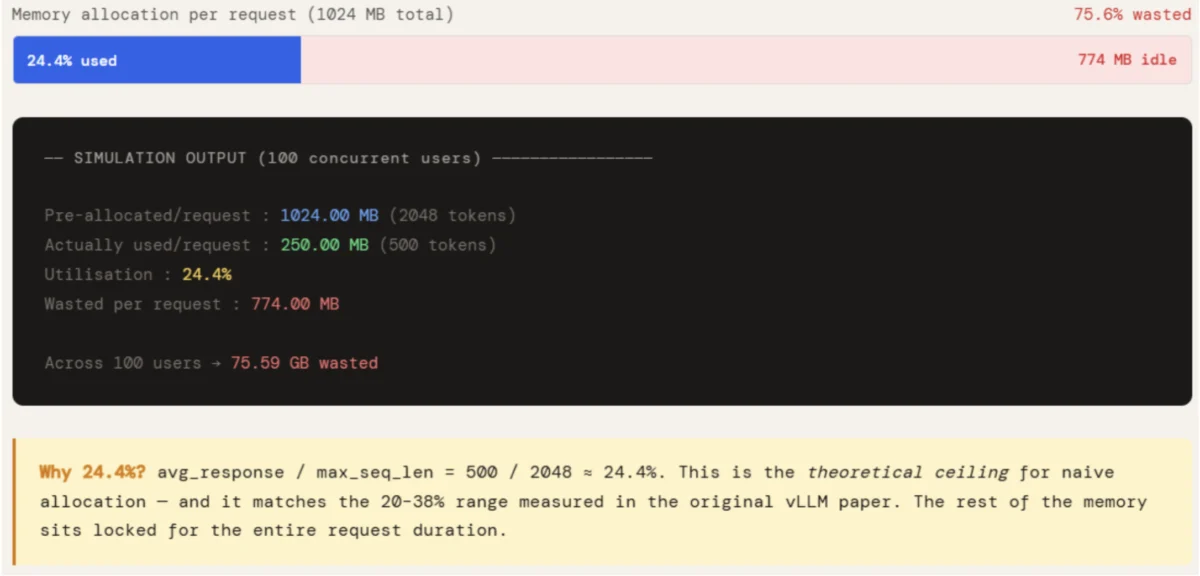
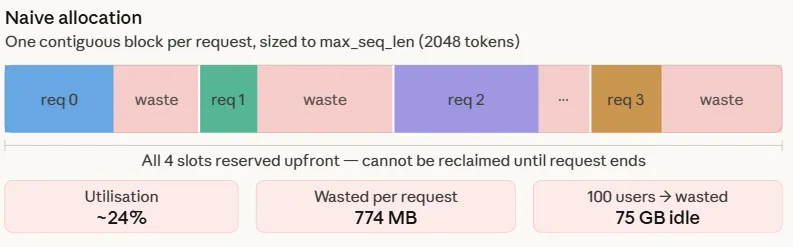
In traditional inference setups, memory is allocated "naively." Because the final length of a model’s response is unknown at the start of a request, the system must reserve a contiguous block of memory equal to the maximum possible sequence length. If a user asks a simple question that results in a 500-token response, but the system has reserved space for 2,048 tokens, over 75% of that allocated memory sits idle.
This leads to two forms of waste: internal fragmentation and reservation waste. Internal fragmentation occurs because the memory is locked to a specific request and cannot be used by others, even if it remains empty. Reservation waste occurs because the system must account for the "worst-case scenario" for every single user. In a production environment with 100 concurrent users, this naive approach can result in upwards of 75 GB of wasted GPU memory—an amount that exceeds the total capacity of an NVIDIA A100 (80GB) or H100 (80GB) GPU. Consequently, the GPU hits an Out-of-Memory (OOM) error despite having the computational cycles to spare, artificially capping the throughput of the service.
The Paged Attention Innovation
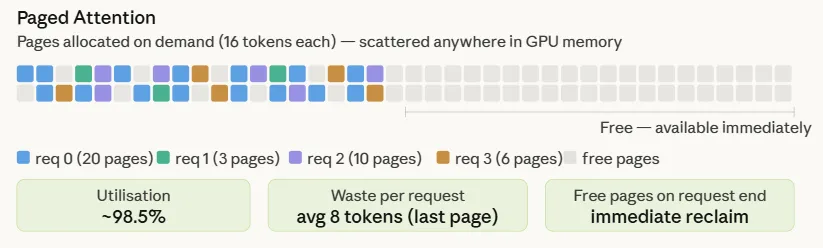
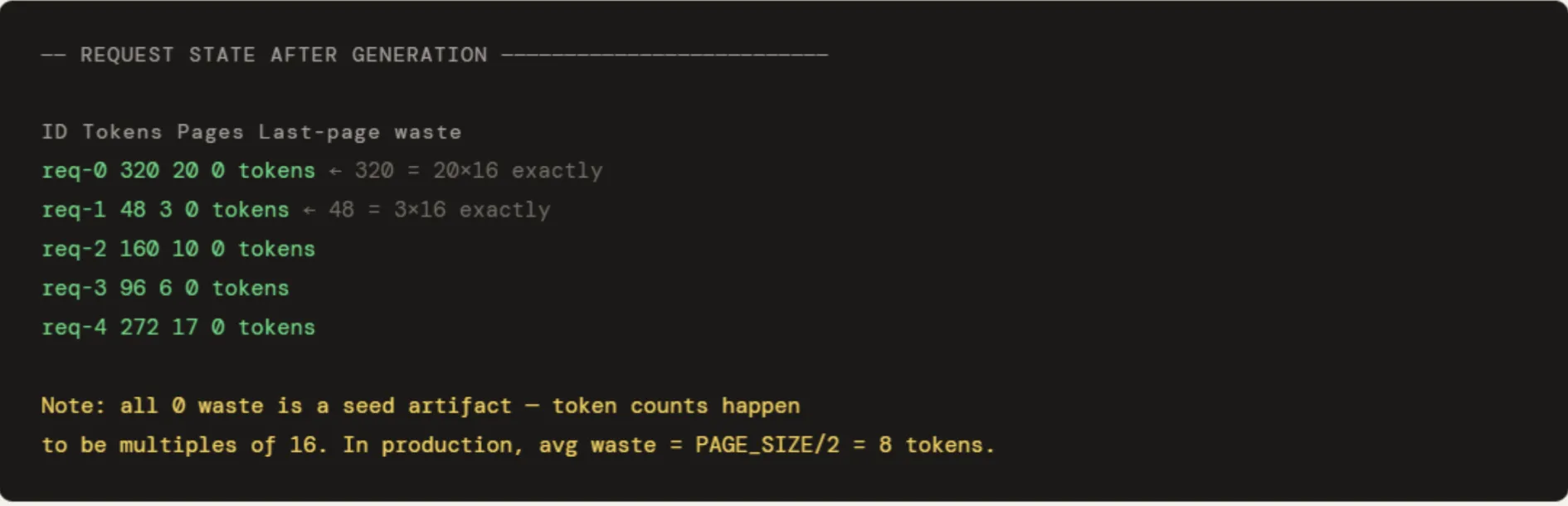
Paged Attention, pioneered by the researchers behind the vLLM framework, solves this by applying the concept of virtual memory to the KV cache. Instead of requiring a single contiguous block of memory for each request, Paged Attention partitions the KV cache into fixed-size "pages." In standard implementations, each page typically holds the KV data for 16 tokens.
These pages are managed through a "Block Table," which maps logical token indices to physical memory locations. When a request begins, the system does not reserve 2,048 slots; it allocates only the pages needed for the initial prompt. As the model generates more tokens and fills a page, the system pulls a new, empty page from a global "Page Pool." These physical pages do not need to be adjacent to one another in the GPU memory. This flexibility allows the system to pack requests tightly, utilizing almost every available byte of HBM.

Copy-on-Write and Prefix Sharing
One of the most powerful features enabled by Paged Attention is "Prefix Sharing" via a Copy-on-Write (CoW) mechanism. In many enterprise applications, multiple users interact with the same system prompt or "instructions" (e.g., "You are a helpful assistant that translates English to French…"). In a naive system, if 10 users are active, the KV cache for that identical 200-token system prompt is stored 10 separate times.
With Paged Attention, the system recognizes that the initial tokens are identical. It allows all 10 requests to point to the same physical pages in memory for the duration of the shared prefix. This results in massive memory savings. For a 200-token system prompt across 10 requests, the system saves approximately 936 MB of memory.
The "Copy-on-Write" logic ensures that as soon as a request diverges—for instance, when the model generates a unique response for User A that differs from User B—the system creates a private copy of only the specific page where the divergence occurs. All subsequent tokens for that user are then stored in newly allocated, private pages. This shared-until-necessary approach maximizes efficiency without risking data cross-contamination between users.
Comparative Data and Performance Metrics
The performance gap between naive allocation and Paged Attention is stark. Simulations measuring memory utilization across various batch sizes (from 10 to 200 concurrent requests) reveal a consistent trend. In a scenario where the average response length is 500 tokens but the maximum sequence length is 2,048, naive systems hover around a 24.4% utilization rate. This percentage remains stagnant regardless of batch size because the waste is structural—it is built into the way memory is reserved.
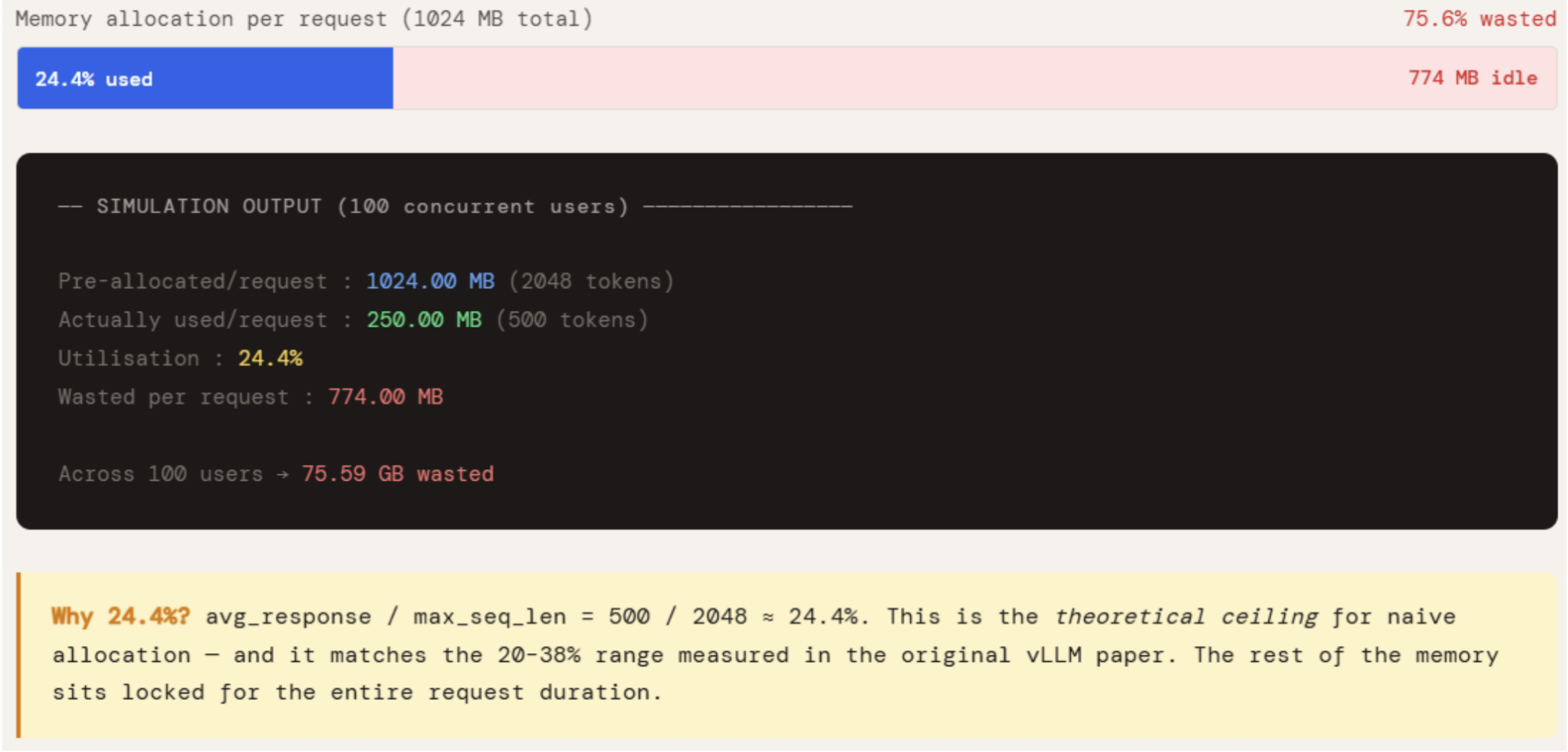
In contrast, Paged Attention systems achieve utilization rates of approximately 98.5%. The only remaining waste is the "tail" of the very last page of a request, which, on average, is only 8 tokens (half of a 16-token page). Because this waste is bounded and does not scale with the maximum sequence length, the efficiency remains high even as models and sequence lengths grow. This 74-percentage-point improvement in utilization translates directly into a 2x to 4x increase in throughput, allowing organizations to serve significantly more users on the same hardware infrastructure.
Timeline and Evolution of Attention Mechanisms
The journey toward Paged Attention represents a rapid evolution in Transformer optimization:

- 2017–2021: Early LLM deployment relied on standard Attention mechanisms, where memory grew quadratically with sequence length, severely limiting context windows.
- 2022: The introduction of FlashAttention optimized the "compute" aspect by making the attention mechanism IO-aware, reducing the number of times data had to be moved between high-speed SRAM and slower HBM.
- 2023: The vLLM team introduced Paged Attention, shifting the focus from compute optimization to memory management. This was the turning point that enabled the "High Throughput" era of LLM serving.
- 2024–Present: Paged Attention has become an industry standard, integrated into major inference engines including NVIDIA’s TensorRT-LLM, Hugging Face’s Text Generation Inference (TGI), and various open-source projects.
Industry Implications and Future Outlook
The implications of Paged Attention extend beyond simple cost savings. For cloud service providers, it enables more competitive pricing for API access. For researchers, it allows for the exploration of much longer context windows (e.g., 128k or 1M tokens), as the memory overhead is no longer as prohibitive.
Furthermore, the "Block Table" architecture provides a foundation for more advanced decoding techniques. Features like speculative decoding—where a smaller model "guesses" tokens and a larger model verifies them—benefit from the flexible memory mapping of Paged Attention. It also simplifies the implementation of "Beam Search" and other complex sampling methods where multiple candidate sequences must be tracked simultaneously.
As models continue to grow in parameter count, the pressure on GPU memory will only intensify. Techniques like Paged Attention are no longer optional "extras" but essential components of the AI stack. By borrowing proven concepts from the early days of operating system design and applying them to the cutting edge of artificial intelligence, engineers have found a way to bridge the gap between the massive memory requirements of LLMs and the physical limitations of current hardware. The result is a more scalable, accessible, and efficient AI ecosystem that can meet the demands of a global user base.












