





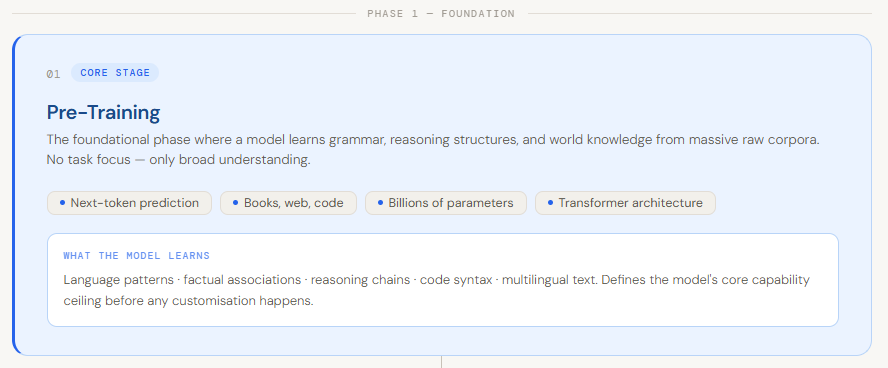
The Foundation of Intelligence: The Pretraining Phase
Pretraining serves as the critical starting point for any large language model, acting as the phase where the system acquires its "world knowledge" and linguistic fluency. During this stage, a model is exposed to vast quantities of unlabeled text data, often measured in the trillions of tokens. Sources typically include the Common Crawl (a massive scrape of the internet), digitized libraries of books, scientific journals, and extensive repositories of programming code such as GitHub.
The primary objective of pretraining is self-supervised learning, specifically "next-token prediction." By attempting to predict the next word in a sequence across billions of examples, the model inherently learns the nuances of grammar, the structures of logic, and the factual relationships between concepts. Industry data suggests that the scale of this phase is immense; for instance, Meta’s Llama 3 was trained on over 15 trillion tokens, requiring thousands of high-end GPUs running for months.

The result of pretraining is a "base model." While highly knowledgeable, a base model is often difficult for humans to interact with directly. If asked a question, a base model might respond with more questions or continue the text as if it were a blog post rather than providing a direct answer. It possesses the raw intelligence of the internet but lacks the specific "instruction-following" behavior required for practical application.
A Chronology of LLM Development: From Transformers to Reasoning Models
The evolution of the LLM pipeline has followed a distinct chronological path, marked by several key milestones in research and architecture:
- The Transformer Era (2017–2018): The publication of the "Attention is All You Need" paper by Google researchers introduced the Transformer architecture, which allowed for parallel processing of text and replaced older recurrent neural network (RNN) designs.
- The Scaling Era (2019–2021): With the release of GPT-2 and GPT-3, researchers discovered "Scaling Laws," which suggested that increasing model parameters, data size, and compute budget led to predictable improvements in performance.
- The Instruction and Alignment Era (2022–2023): The launch of ChatGPT popularized the use of Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), shifting the focus from raw scale to usability and safety.
- The Efficiency and Reasoning Era (2024–Present): Recent developments have focused on making models smarter and cheaper. Techniques like LoRA and QLoRA have democratized fine-tuning, while new algorithms like Group Relative Policy Optimization (GRPO) have introduced advanced reasoning capabilities, as seen in models like DeepSeek-R1.
Refinement through Supervised Fine-Tuning (SFT)
Once a base model is established, it undergoes Supervised Fine-Tuning (SFT). This stage is designed to bridge the gap between a model that understands language and a model that understands instructions. In SFT, the model is trained on a much smaller, high-quality dataset consisting of prompt-response pairs. These pairs are typically written or verified by humans to ensure the model learns the correct format for helpful interaction.
During SFT, the model’s weights are adjusted to minimize the difference between its generated output and the "gold standard" human response. This process is vital for setting the tone and style of the model. For example, a model intended for medical use would be fine-tuned on clinical dialogues, while a coding assistant would be fine-tuned on Python or C++ documentation and bug-fix examples. Data from leading AI labs indicates that even a few thousand high-quality SFT examples can significantly outperform millions of lower-quality automated examples, emphasizing the "quality over quantity" shift in this stage of the pipeline.
Democratizing AI: LoRA and QLoRA Techniques
One of the greatest challenges in the LLM lifecycle is the sheer cost of fine-tuning. Updating all parameters of a 70-billion-parameter model requires massive VRAM (Video Random Access Memory), often exceeding the capacity of even high-end enterprise GPUs. To solve this, researchers developed Low-Rank Adaptation (LoRA).
LoRA operates on a mathematical shortcut: instead of updating the entire weight matrix of the model, it adds two much smaller matrices (low-rank matrices) to the layers. During training, the original model weights are "frozen," and only these small matrices are updated. This reduces the number of trainable parameters by up to 10,000 times, making it possible to fine-tune large models on consumer-grade hardware.

Quantized LoRA (QLoRA) takes this efficiency further by compressing the base model into 4-bit precision. This allows a model that would normally require 140GB of VRAM to fit into less than 40GB without a significant loss in accuracy. These techniques have been instrumental in the explosion of the "Open Source" AI movement, allowing independent developers to create specialized versions of models like Llama or Mistral for niche applications.
Alignment and Human Preference: The Role of RLHF
Even after SFT, models can occasionally hallucinate, provide biased answers, or fail to follow complex nuances of human preference. Reinforcement Learning from Human Feedback (RLHF) is the standard solution for these issues. The process involves three distinct steps:
- Sampling: The model generates multiple responses to the same prompt.
- Ranking: Human evaluators rank these responses from best to worst based on criteria like helpfulness, honesty, and harmlessness.
- Reward Modeling: A separate "reward model" is trained to predict what a human would prefer. The LLM is then optimized using algorithms like Proximal Policy Optimization (PPO) to maximize the "score" given by the reward model.
RLHF is the primary reason modern AI assistants feel "polite" and "safe." However, it is a computationally expensive and complex process. Industry analysts note that the "alignment tax"—the potential for a model to become less creative as it becomes safer—remains a central topic of debate among AI safety researchers.

The New Frontier: Reasoning and GRPO
The most recent innovation in the training pipeline is the move toward structured reasoning through Group Relative Policy Optimization (GRPO). Unlike traditional RLHF, which compares a model’s output to a static reward model, GRPO evaluates a group of generated responses relative to one another. This is particularly effective for mathematical and logical tasks where there is a clear "right" answer or a "best" step-by-step reasoning path.
GRPO encourages the model to show its "chain of thought." By rewarding models that arrive at the correct answer through logical intermediate steps, researchers have found that they can "unlock" reasoning capabilities that were latent in the base model. This technique was a cornerstone in the development of recent reasoning-focused models, which have shown a marked improvement in competitive programming and advanced mathematics benchmarks compared to their predecessors.
Production Deployment and Optimization
The final stage of the LLM pipeline is deployment, where the model is transitioned from a research environment to a production system capable of serving thousands of users. Deployment is less about "learning" and more about "inference efficiency." Because LLMs are "autoregressive" (they generate text one word at a time), they can be slow and expensive to run.

To mitigate this, engineers use several optimization strategies:
- Quantization: Converting model weights to lower precision (8-bit or 4-bit) to speed up calculations.
- KV Caching: Storing previously calculated values to avoid redundant computations during the generation of a long sentence.
- Continuous Batching: A technique used by inference engines like vLLM to process multiple user requests simultaneously, maximizing GPU throughput.
Current industry standards for deployment emphasize "Time to First Token" (TTFT) and "Tokens Per Second" (TPS) as the primary metrics for success. For enterprise-grade applications, models are often deployed within Docker containers and managed via Kubernetes, ensuring they can scale up or down based on user demand.
Broader Impact and Industry Implications
The maturation of the LLM training pipeline has profound implications for the global economy and the future of software development. We are seeing a shift from "Software as a Service" (SaaS) to "Model as a Service" (MaaS). Companies that can master this pipeline gain a significant competitive advantage by creating proprietary "intelligence" tailored to their specific data.

However, the environmental and economic costs cannot be ignored. The energy consumption required for the pretraining phase of a single frontier model is equivalent to the annual usage of hundreds of households. Furthermore, the concentration of compute power in the hands of a few "hyperscalers" (Google, Microsoft, Amazon, Meta) has raised concerns about the centralization of AI power.
Despite these challenges, the move toward efficiency—driven by LoRA, QLoRA, and more efficient reinforcement learning like GRPO—suggests a future where high-performance AI is more accessible. As the pipeline continues to evolve, the focus is expected to shift from simply making models "larger" to making them more "logical," efficient, and deeply integrated into the fabric of daily digital life. The transition from raw data to a deployable intelligent agent is now a well-defined science, setting the stage for the next generation of autonomous and reasoning-capable systems.












