




The rapid evolution of large language models (LLMs) has increasingly pushed the boundaries of context length, with modern frontier models now targeting windows of one million tokens or more. However, the fundamental architecture of the transformer remains constrained by the scaled dot-product attention (SDPA) mechanism, which scales quadratically—$Theta(N^2)$—in both compute and memory relative to the sequence length $N$. While FlashAttention provided a critical breakthrough via IO-aware tiling to reduce the memory footprint, it did not alter the underlying compute scaling. To address this persistent bottleneck, researchers at Nous Research have unveiled Lighthouse Attention, a training-only hierarchical selection method that achieves significant end-to-end wall-clock speedups during pretraining while maintaining the model’s ability to function as a dense-attention system during inference.
The Evolution of the Long-Context Problem
The "quadratic wall" has long been the primary obstacle for researchers attempting to train models on massive sequences. In a standard transformer, every token must attend to every other token, meaning a doubling of the context length results in a fourfold increase in the computational cost of the attention layers. For industry-scale pretraining, this translates to massive energy consumption and the requirement for vast clusters of high-end GPUs, such as the NVIDIA H100 or the newer Blackwell B200.
Previous attempts to mitigate this cost generally fell into the category of sparse attention. Methods like Hierarchical Sparse Attention (HISA), Multi-head Block Attention (MoBA), and Native Sparse Attention (NSA) attempted to reduce complexity by attending to only a subset of the sequence. However, these methods typically relied on asymmetric compression—pooling only the key and value projections while leaving the query projection at full resolution. This design choice meant that while the memory load was reduced, the computational complexity remained $O(N cdot S cdot d)$, where $S$ is the compressed length. Furthermore, these methods often required custom, hand-optimized kernels that could not easily leverage the highly optimized dense-attention kernels provided by hardware manufacturers.
Lighthouse Attention represents a departure from these traditional sparse methods by prioritizing "recoverability" and symmetric pooling. The central thesis of the Nous Research team is that a training-time optimization should not permanently "lock" a model into a sparse configuration. Instead, the optimization should accelerate the learning process and then be removable, leaving behind a weight set that performs optimally under standard dense attention.
Technical Architecture: The Four-Stage Lighthouse Pipeline
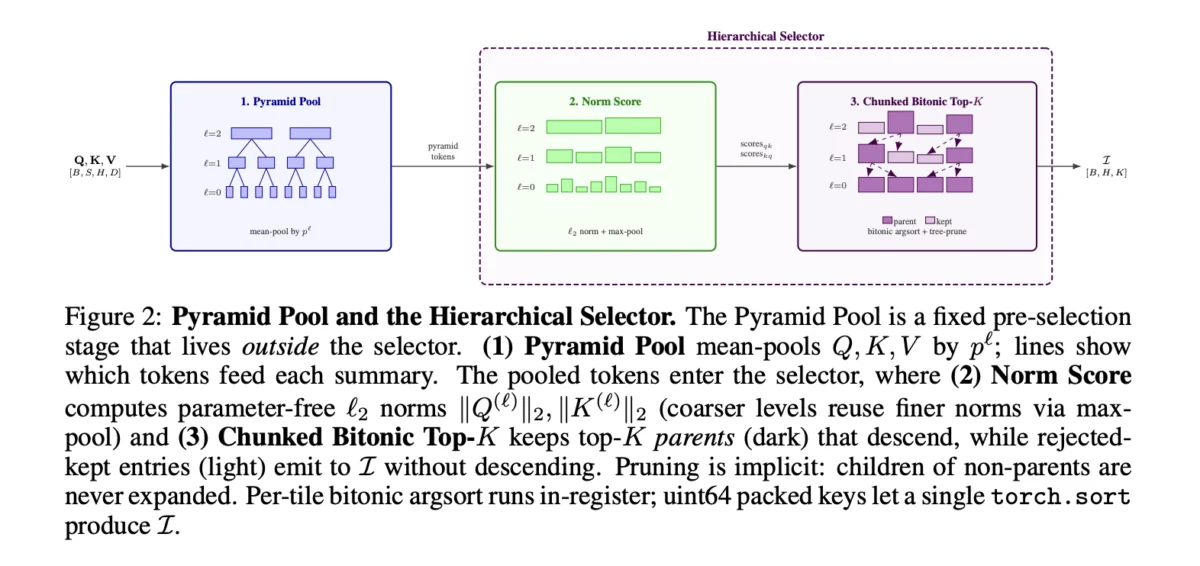
Lighthouse Attention operates as a wrapper around the attention mechanism, utilizing a four-stage pipeline that processes the Query (Q), Key (K), and Value (V) projections before they reach the core attention kernel.
The first stage involves the construction of an $L$-level pyramid through average pooling. Unlike previous methods, Lighthouse applies this pooling symmetrically to Q, K, and V. With a pooling factor $p$, each level of the pyramid summarizes a set of base positions into a single token. This creates a multi-scale representation where coarser levels provide a global overview and finer levels provide local detail. This pyramid construction is highly efficient, requiring only linear $Theta(N)$ time and memory.
The second stage introduces a parameter-free scoring mechanism. Each entry in the pyramid is assigned a scalar score based on its per-head $L_2$ norm. These scores determine the importance of specific spans of the sequence. To ensure that the selection does not collapse into a narrow focus, the system employs a fused chunked-bitonic top-K kernel. This kernel performs stratified selection, partitioning the score stream into fixed chunks and maintaining a local buffer of high-scoring entries. This ensures that the attention mechanism maintains broad coverage across the entire sequence length. Crucially, the coarsest level of the pyramid is always retained in full, providing a "safety net" that guarantees every base position has at least one representative in the attention calculation.

In the third stage, the selected entries are gathered into a contiguous, dense sub-sequence. This is a vital design choice: by assembling the selected tokens into a dense format, Lighthouse can utilize stock FlashAttention kernels—the same ones used in the dense baseline. This avoids the need for specialized sparse kernels and allows the model to benefit from the continuous optimizations made to standard attention libraries. The resulting sub-sequence length $S$ is significantly smaller than $N$; for a one-million-token sequence, $S$ might be as low as 65,000.
Finally, in the fourth stage, the output of the attention call is scattered back to the original base positions using a deterministic integer-atomic scatter kernel. This ensures that the final output remains fully dense and compatible with the rest of the transformer block.
Benchmarking Efficiency and Throughput
The computational advantages of symmetric pooling are most evident in the shift of the attention math. By pooling queries alongside keys and values, the complexity of the attention call drops from $O(N cdot S cdot d)$ to $O(S^2 cdot d)$. In long-context scenarios, this reduction is the primary driver of latency improvement.
Nous Research conducted extensive benchmarking on the NVIDIA B200 architecture. At a context length of 512,000 tokens, Lighthouse Attention demonstrated a 21-fold speedup in the forward pass and a 17.3-fold speedup in the combined forward and backward pass compared to a cuDNN-backed SDPA baseline. When measured end-to-end in a full pretraining environment, these improvements translated to a wall-clock speedup of 1.40x to 1.69x.
Asymptotically, Lighthouse places attention in the same class as linear attention and State Space Models (SSMs) while preserving the superior recall properties associated with softmax attention. By setting the number of pyramid levels $L$ relative to the sequence length and selection budget, the total per-layer compute becomes $Theta(T cdot d)$, effectively neutralizing the quadratic growth of the sequence length $T$.
The Two-Stage Training Recipe and Model Recoverability
A significant concern with sparse training methods is whether the resulting model will remain "competent" when switched back to dense attention for inference. To test this, the researchers implemented a two-stage training recipe.
In Stage 1, the model is trained for the majority of its token budget using Lighthouse Attention. This allows the model to process data at roughly double the throughput of a standard dense run. In Stage 2, the Lighthouse selection is disabled, and training resumes using standard dense SDPA for a short "tail" period.
Experiments were conducted using a 530-million-parameter Llama-3-style decoder trained on the C4 dataset with a 98,304-token context. The results showed that upon switching to dense attention, the model’s training loss spiked transiently as it adjusted to the new attention pattern. However, the loss recovered within 1,000 to 1,500 steps, eventually falling below the loss level of a dense-from-scratch baseline. At the conclusion of 16,000 steps, all Lighthouse-trained models achieved final losses between 0.6980 and 0.7102, outperforming the dense baseline’s loss of 0.7237. This suggests that hierarchical selection may actually act as a regularizer, helping the model learn more robust representations.

Retrieval Performance and Long-Context Stability
Beyond raw training loss, the effectiveness of a long-context model is often measured by its ability to retrieve specific information from large datasets. The research team employed a "Needle-in-a-Haystack" (NIAH) evaluation to test this capability.
The test involved hiding a single passkey digit within a sequence of random alphanumeric filler at various depths across context lengths ranging from 4,000 to 96,000 tokens. The dense-from-scratch baseline achieved a mean retrieval rate of 0.72. Lighthouse configurations generally matched or exceeded this performance. Specifically, a configuration using a "dilated" scorer with a selection budget ($k$) of 2,048 achieved a retrieval rate of 0.76.
Interestingly, the ablation studies revealed a trade-off between throughput and retrieval accuracy. While a "norm-based" scorer was roughly 9% cheaper in terms of B200-hours, it slightly hampered retrieval performance compared to the more expensive dilated scorer. This provides practitioners with a choice: optimize for maximum training speed if the downstream task is loss-driven, or invest in a more complex scorer if high-precision retrieval is the goal.
Scaling to One Million Tokens with Context Parallelism
For sequences exceeding 100,000 tokens, individual GPUs typically run out of memory due to the size of activations and optimizer states. To handle these regimes, Lighthouse was designed to integrate seamlessly with Context Parallelism (CP).
In a CP setup, the sequence is sharded across multiple GPUs. Because the Lighthouse pyramid pooling and selection logic run shard-locally, they require no inter-rank communication. The gathered sub-sequence is dense, meaning it can participate in standard "ring attention" protocols without the need for the specialized sparse-aware collectives required by other methods.
Using 32 Blackwell GPUs (4 nodes) with a CP degree of 8, the team successfully demonstrated 1M-token training. The speedup ratio observed on a single device was preserved in the multi-node environment, confirming that Lighthouse is a viable solution for the next generation of ultra-long-context models.
Implications for the Future of AI Development
The introduction of Lighthouse Attention by Nous Research suggests a shift in how the industry approaches the scaling of transformers. By treating sparsity as a training-time optimization rather than an architectural permanence, Lighthouse provides a "best of both worlds" scenario: the speed of sparse methods during the expensive pretraining phase and the reliability of dense methods during the critical inference phase.
The fact that Lighthouse requires no new learnable parameters and no auxiliary losses makes it a highly attractive "drop-in" solution for existing training pipelines. As context lengths continue to grow, the ability to bypass the quadratic compute wall while utilizing standard, highly optimized hardware kernels will likely become a standard requirement for efficient AI development. Future work in this area is expected to explore the application of Lighthouse to other modalities, such as vision and audio, where hierarchical structures are naturally present.












