

The landscape of generative artificial intelligence is shifting from static image synthesis toward the creation of sophisticated "world models"—systems capable of simulating physical environments through high-fidelity video. NVIDIA Research has announced the release of SANA-WM, a 2.6-billion-parameter open-source world model designed to overcome the primary bottlenecks of contemporary video generation: the massive computational requirements for training and the inability of most models to produce long-duration, high-resolution sequences on consumer-grade hardware. Built upon the SANA-Video framework, SANA-WM is capable of generating 60-second, 720p video clips with precise six-degree-of-freedom (6-DoF) camera control, all while maintaining a footprint small enough for single-GPU inference.
The development of world models is increasingly viewed as a cornerstone for the future of embodied AI, robotics, and digital twin simulations. However, the industry has long struggled with a "compute wall." Competitive baselines often require multi-GPU clusters for inference or are forced to sacrifice resolution and duration to remain within memory budgets. SANA-WM represents a significant departure from these limitations, utilizing a Diffusion Transformer (DiT) architecture optimized for efficiency and temporal stability.
Architectural Innovation: Overcoming Quadratic Complexity
The core technical challenge in minute-long video generation is the scaling of attention mechanisms. Traditional softmax attention, used in most large-scale transformers, exhibits memory and compute complexity that grows quadratically with sequence length. In the context of a 60-second video at 24 frames per second, a model must process nearly 1,000 latent frames. For standard architectures, this volume of data leads to memory exhaustion even on high-end enterprise hardware.
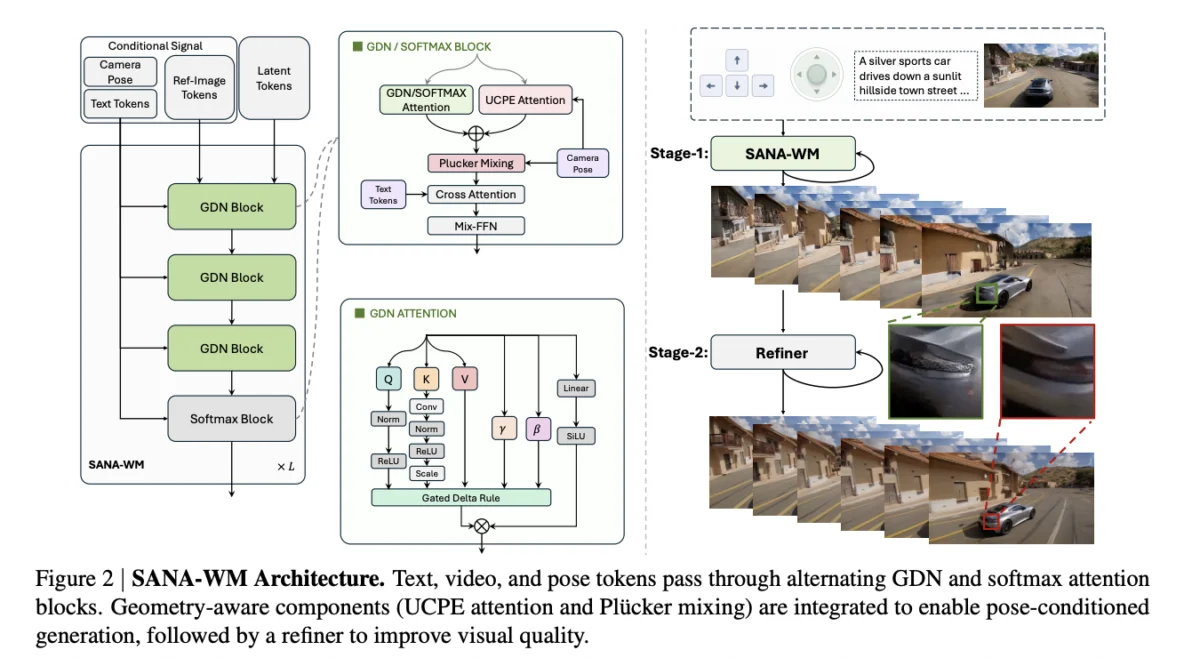
To resolve this, NVIDIA’s research team implemented a hybrid linear attention mechanism centered on a frame-wise Gated DeltaNet (GDN). While previous iterations like SANA-Video utilized cumulative ReLU-based linear attention to maintain a constant-size recurrent state, those systems lacked a decay mechanism. Without decay, past frames accumulated with equal weight, leading to visual "drift" and structural degradation over long sequences.
The frame-wise GDN in SANA-WM introduces a decay gate and a delta-rule correction. This allows the model to down-weight stale information while updating only the residual difference between the target value and the current state. Consequently, the recurrent state remains at a constant size regardless of the video length. To ensure training stability, the researchers introduced an algebraic key-scaling approach, scaling keys by the inverse square root of the product of the head dimension and spatial tokens. This mathematical adjustment eliminated the "NaN" (Not a Number) divergence events that frequently plague deep linear recurrence models during training.
The final backbone of SANA-WM consists of 20 transformer blocks: 15 frame-wise GDN blocks interleaved with five softmax attention blocks. This hybrid approach allows the GDN to handle the bulk of the temporal processing efficiently, while the softmax blocks provide the exact long-range recall necessary for spatial consistency.
Precision Camera Control via Dual-Branch Engineering
For a world model to be useful in robotics or professional simulation, it must do more than generate "plausible" motion; it must follow a specific, metric-scale trajectory. SANA-WM achieves this through a dual-branch camera control system that operates at different temporal resolutions.

The first branch, known as the Unified Camera Positional Encoding (UCPE), operates at the latent-frame rate. It computes a ray-local camera basis from the camera-to-world pose and intrinsics, applying this geometric data to the attention heads. This provides the model with a global understanding of the 6-DoF trajectory.
The second branch, Plücker Mixing, addresses the nuances of temporal compression. Because the model’s Variational Autoencoder (VAE) compresses eight raw frames into a single latent token, a single token must represent eight distinct camera poses. The Plücker branch computes pixel-wise raymaps for all eight frames, packing them into a 48-channel tensor. This high-frequency data is injected into the transformer blocks, ensuring that the generated video adheres to the intended path with sub-frame precision. Internal testing on the OmniWorld dataset demonstrated that this dual-branch approach significantly outperformed single-method controls in Camera Motion Consistency (CamMC).
A Two-Stage Pipeline for High-Fidelity Output
Recognizing that long-horizon generation often leads to subtle structural artifacts, NVIDIA implemented a two-stage refinement pipeline. The first stage generates the base video sequence, ensuring spatiotemporal consistency. The second stage serves as a refiner, utilizing a 17-billion-parameter LTX-2 model modified with rank-384 LoRA adapters.
This refiner employs "truncated-σ flow matching," a process where stage-one latents are perturbed with controlled noise. The refiner then maps this noisy input toward a high-fidelity target in just three denoising steps. This process has proven highly effective at reducing visual drift. On "Hard-Trajectory" benchmarks, the refiner reduced the imaging-quality degradation score (ΔIQ) from 3.09 to a mere 0.31, effectively preserving visual clarity from the first second of the video to the sixtieth.
Data Annotation and Synthetic Refinement
The efficacy of SANA-WM is rooted in a robust data annotation pipeline. Training a camera-controlled model requires metric-scale 6-DoF pose data, which is rarely present in standard internet video datasets. NVIDIA’s researchers modified the VIPE (Visual Pose Estimation) engine, replacing its depth backend with Pi3X for long-sequence consistency and MoGe-2 for accurate metric scaling.
The team also extended bundle adjustment protocols to treat focal lengths as per-frame variables. This allowed for the successful annotation of diverse internet videos where camera zoom or focal length might change mid-clip. The resulting training corpus comprised over 212,000 clips sourced from both real-world data (such as SpatialVID-HQ and MiraData) and synthetic environments (OmniWorld and Sekai Game).
For static 3D scenes in the DL3DV dataset, the team utilized 3D Gaussian Splatting to render diverse one-minute camera paths. These renders were then processed through a "DiFix3D" refiner to eliminate common splatting artifacts, resulting in high-quality synthetic training data with perfectly known camera extrinsics.
Training Chronology and Performance Metrics
The training of SANA-WM was conducted on a cluster of 64 NVIDIA H100 GPUs over a period of approximately 18.5 days. The process began with a 3.5-day VAE pre-adaptation phase, followed by a 15-day, four-stage progressive DiT training schedule. This schedule started with low-resolution, short-duration clips (256p, 4-second) and scaled up to the final 720p, 60-second native generation capability.

The efficiency gains were bolstered by custom fused Triton kernels for GDN operations, which provided a 1.5x to 2x throughput improvement during the training phase. In inference benchmarks, SANA-WM demonstrated a massive lead over existing open-source models. While models like LingBot-World and Matrix-Game 3.0 require eight GPUs to generate 720p video at low throughput, SANA-WM achieves a throughput of 24.1 videos per hour on a single H100.
Furthermore, the distilled variant of the model, utilizing NVFP4 quantization, can denoise a full 60-second 720p clip in just 34 seconds on a single consumer-grade RTX 5090 GPU. This makes the model accessible not only to well-funded research labs but also to individual developers and smaller startups.
Broader Impact and Industry Implications
The release of SANA-WM as an open-source project (available via the NVlabs/Sana GitHub repository) marks a significant milestone in the democratization of advanced AI simulation. By providing the weights and the codebase under an accessible license, NVIDIA is positioning SANA-WM as a foundational tool for the next generation of AI research.
Industry analysts suggest that the implications of this model extend far beyond video generation. In the field of robotics, SANA-WM can serve as a simulator for training reinforcement learning agents, allowing them to "experience" millions of hours of varied, camera-controlled environments without the need for physical hardware. In the realm of autonomous vehicles, the model’s ability to generate long, consistent sequences of city and nature environments could be used to simulate rare "edge-case" driving scenarios.
Moreover, the model’s efficiency challenges the prevailing narrative that high-quality generative AI must remain the exclusive domain of massive data centers. By optimizing the underlying mathematics of attention and refinement, NVIDIA has demonstrated that "minute-scale" world modeling is possible on a single GPU.
As the AI community begins to integrate SANA-WM into various workflows, the focus will likely shift toward expanding its 3D memory capabilities. While the model is highly proficient at temporal consistency, researchers noted that it currently lacks explicit 3D scene memory, which can lead to drift in highly dynamic scenes or when returning to previously viewed areas after a long duration. Nevertheless, SANA-WM stands as a powerful proof of concept for efficient, high-resolution, and long-form world modeling, setting a new benchmark for the open-source AI ecosystem.