The landscape of artificial intelligence is undergoing a seismic shift as the performance delta between proprietary frontier models and transparent, open-source alternatives continues to collapse. In a landmark announcement on March 11, 2026, NVIDIA officially introduced Nemotron 3 Super, a 120 billion parameter reasoning model specifically architected to power the next generation of complex, multi-agent applications. This release marks a critical juncture for the industry, providing developers with a high-intelligence reasoning engine that maintains the efficiency required for large-scale enterprise deployment.
Nemotron 3 Super is strategically positioned within NVIDIA’s broader AI roadmap, serving as the mid-tier powerhouse between the lightweight 30 billion parameter Nemotron 3 Nano and the upcoming 500 billion parameter Nemotron 3 Ultra, which is slated for release later in 2026. By delivering up to seven times higher throughput and doubling the accuracy of previous iterations, NVIDIA is addressing the primary bottleneck in agentic AI: the trade-off between cognitive depth and inference speed.
The Evolution of the Nemotron Ecosystem
The release of Nemotron 3 Super represents the culmination of a multi-year effort by NVIDIA to democratize high-end reasoning capabilities. Historically, models with over 100 billion parameters were the exclusive domain of large-scale cloud providers, often locked behind restrictive APIs. NVIDIA’s decision to open-source the entire stack—including weights, training datasets, libraries, and reinforcement learning environments—signals a commitment to an open AI ecosystem that challenges the dominance of closed-source giants.
This model is not merely an incremental update; it is a foundational shift in how large language models (LLMs) are trained and deployed. While the previous generation relied on standard transformer architectures, Nemotron 3 Super utilizes a sophisticated hybrid framework. This architectural evolution is designed to meet the demands of "Agentic AI," where models do not just respond to prompts but plan, verify, and execute multi-step tasks across distributed systems.

Architectural Innovation: The Hybrid Mamba-Attention MoE Model
At the core of Nemotron 3 Super’s performance are five technological breakthroughs, often referred to by NVIDIA engineers as the "Five Miracles." These innovations allow the model to process information with unprecedented efficiency:
- Hybrid Mamba-Attention Mechanism: By combining the linear scaling of State Space Models (Mamba) with the proven contextual strengths of the Attention mechanism, the model handles massive context windows without the exponential computational costs associated with traditional Transformers.
- Mixture-of-Experts (MoE) Integration: The model employs a sparse MoE architecture, meaning that for any given task, only a fraction of the 120 billion parameters are active. This drastically reduces the compute required per token, facilitating the 7x throughput increase.
- Advanced Quantization (NVFP4): Engineered for NVIDIA’s latest hardware, specifically the DGX Spark, the model supports NVFP4 quantization. This allows for massive parameter counts to run on smaller hardware footprints without a significant loss in reasoning accuracy.
- Multi-Agent Orchestration Logic: Unlike general-purpose models, Nemotron 3 Super’s weights are fine-tuned for "agentic" behaviors—specifically the ability to call tools, verify its own logic, and hand off tasks to specialized sub-models.
- Data-Driven Curated Scaling: The model was trained on a massive pipeline of 10 trillion curated tokens. This was supplemented by an additional 10 billion tokens focused exclusively on high-level mathematics, Python programming, and logical syllogisms.
Redefining Developer Control with Reasoning Budgets
One of the most significant features introduced with Nemotron 3 Super is the concept of "Reasoning Budgets." NVIDIA has recognized that in an enterprise environment, not every query requires the full cognitive weight of a 120B model. A customer service chatbot needs speed, while a drug discovery agent needs deep, iterative thought.
Through a new set of API-level controls, developers can now dynamically adjust the model’s internal "thought process" for each task. This allows for:
- Low-Effort Mode: Optimized for high-speed, low-latency tasks like summarization or basic data entry.
- Standard Reasoning: Balanced for general conversation and tool-calling.
- Uncapped Deep-Dive: The model engages in extensive self-verification and "chain-of-thought" processing, ideal for complex debugging or strategic planning.
To simplify the deployment of these modes, NVIDIA’s research team has identified a "Golden Configuration" for optimal results. For most multi-agent workflows, NVIDIA recommends setting the Temperature to 1.0 and Top P to 0.95. This mathematical balance allows the model to remain creative enough to solve novel problems while staying anchored to logical precision.
Performance Benchmarks and Industry Analysis
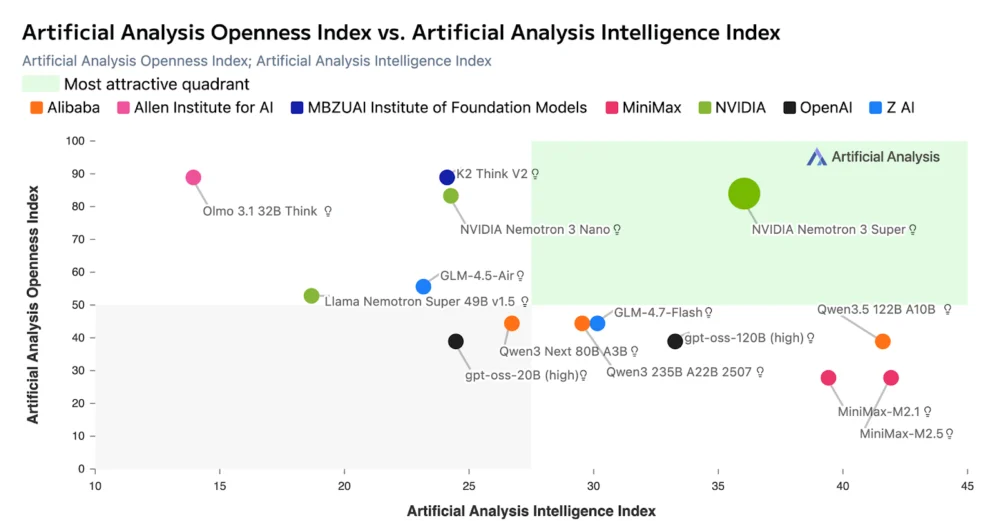
Independent analysis by firms such as Artificial Analysis has already placed Nemotron 3 Super in the "most attractive" quadrant of the AI market. This categorization is based on the model’s "Openness Score" paired with its "Quality Score." While proprietary models like GPT-4o and Gemini 1.5 Pro maintain a slight edge in some creative writing benchmarks, Nemotron 3 Super has shown parity or superiority in coding, structured data extraction, and multi-step reasoning.
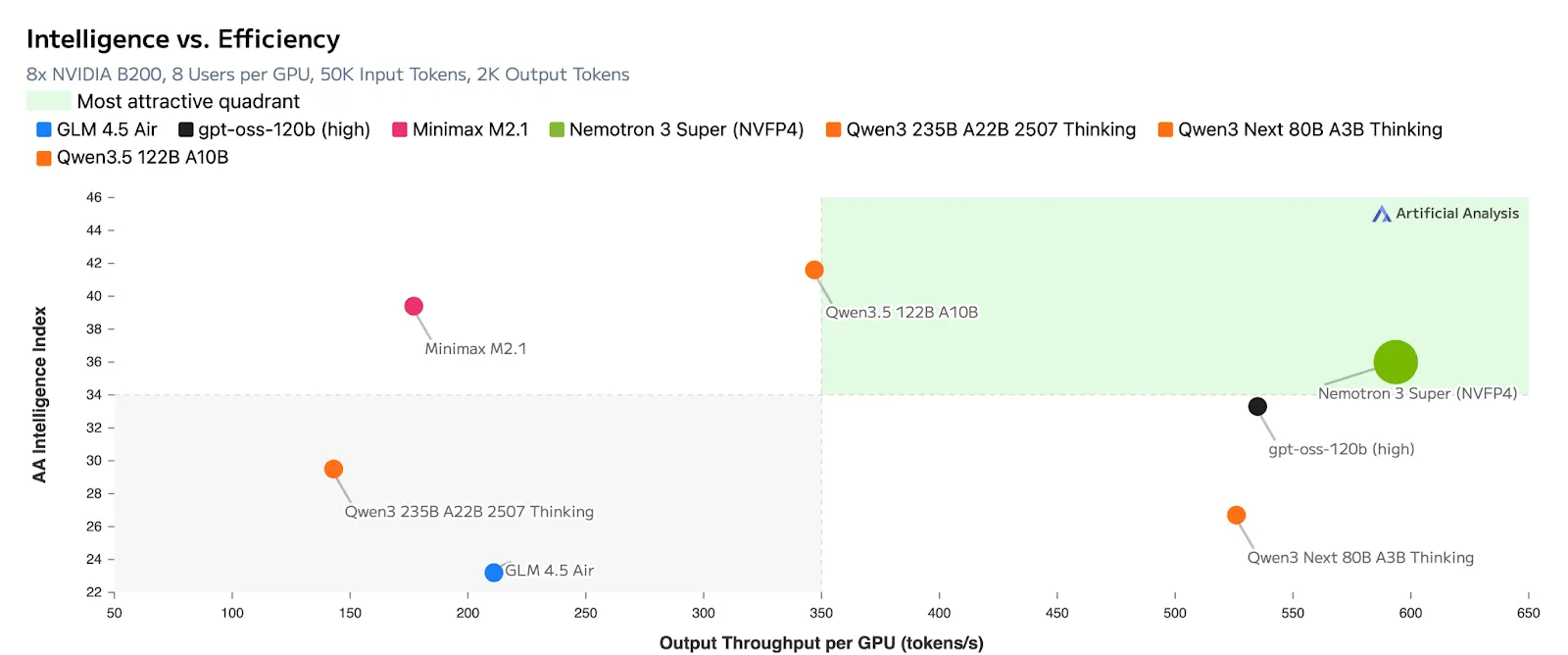
The model’s efficiency is particularly notable in terms of output tokens per GPU. By utilizing the hybrid Mamba-Attention MoE structure, Nemotron 3 Super can serve significantly more users on a single H200 or B200 cluster than previous-generation models of similar size. For enterprises, this translates directly into a lower Total Cost of Ownership (TCO) for AI infrastructure.
Real-World Applications in Enterprise Workflows
NVIDIA’s internal testing and early-access partner reports highlight several key areas where Nemotron 3 Super is already making an impact:
- Software Engineering: In large-scale repositories, the model acts as a lead architect, coordinating smaller "coding agents" to refactor legacy code, write unit tests, and maintain documentation across different programming languages.
- Financial Modeling: The model’s ability to process long-context financial reports while maintaining strict logical consistency makes it ideal for automated risk assessment and trend forecasting.
- Supply Chain Orchestration: By serving as the "brain" of a multi-agent system, Nemotron 3 Super can manage various sub-agents responsible for inventory tracking, logistics, and vendor communication, synthesizing their data into actionable executive summaries.
Availability and Deployment
Nemotron 3 Super is available immediately on Hugging Face and the NVIDIA NGC catalog. It is released in several quantization formats, including BF16 for standard research, FP8 for high-speed inference, and the specialized NVFP4 for deployment on NVIDIA DGX Spark systems.
The full release of the training stack is a strategic move intended to foster a community of developers who can fine-tune the model for specific vertical industries, such as healthcare, legal, and automotive. By providing the "blueprints" alongside the "engine," NVIDIA is ensuring that Nemotron 3 Super becomes a standard pillar of the open-source AI community.
Broader Implications for the AI Market
The launch of Nemotron 3 Super is more than just a product release; it is a statement of intent regarding the future of AI development. By focusing on "Agentic AI" and "Multi-Agent Systems," NVIDIA is moving the conversation away from simple chat interfaces and toward autonomous digital workers.

Industry analysts suggest that this move could force proprietary model providers to reconsider their pricing and "black box" strategies. As open-source models achieve 120B+ parameter scales with high-efficiency architectures, the value proposition of closed APIs begins to shift toward specialized services rather than raw intelligence.
Furthermore, the integration of State Space Models like Mamba into a production-grade 120B parameter model proves that the industry is ready to move beyond the limitations of the original Transformer paper. This hybrid approach likely sets the stage for the 500B Nemotron 3 Ultra, which many expect will challenge the absolute ceiling of current AI capabilities when it arrives later this year.
In conclusion, NVIDIA’s Nemotron 3 Super represents a sophisticated fusion of hardware optimization and software intelligence. For developers and enterprises, it provides a powerful, transparent, and controllable engine for the next era of reasoning-driven AI applications. As the industry moves toward 2027, the success of this model will likely be measured not just by its benchmarks, but by the complexity of the autonomous agent ecosystems it helps create.