




The transition of a machine learning (ML) model from a local development environment to a live production ecosystem represents the most volatile phase of the artificial intelligence lifecycle. While a model may demonstrate exceptional accuracy on static validation and test datasets, the transition to real-world application introduces unpredictable variables, including data distribution shifts, evolving user behaviors, and unforeseen system constraints. Industry reports suggest that a significant percentage of machine learning initiatives fail at this juncture, often because offline performance metrics do not align with online business outcomes. To mitigate these risks, modern MLOps (Machine Learning Operations) frameworks have shifted toward controlled rollout strategies designed to validate candidate models under real production conditions while strictly limiting the "blast radius" of potential failures.
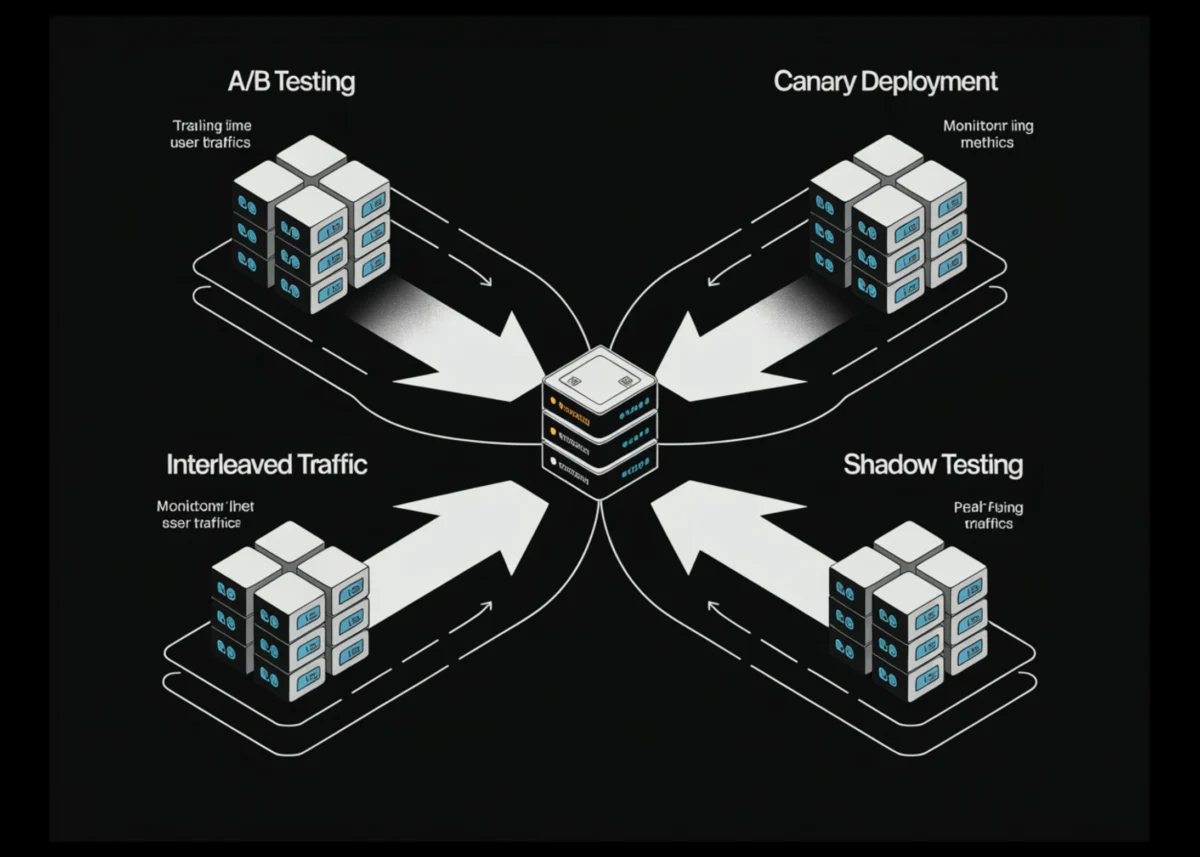
The necessity of these strategies is underscored by the inherent limitations of offline evaluation. In a controlled environment, data is historical and cleaned; in production, data is streaming, noisy, and subject to "concept drift"—a phenomenon where the statistical properties of the target variable change over time. Consequently, ML engineering teams at organizations such as Google, Netflix, and Meta have pioneered specific deployment methodologies—A/B testing, Canary testing, Interleaved testing, and Shadow testing—to ensure system reliability and maintain user trust.
The Evolution of Machine Learning Deployment Pipelines
Historically, software deployment relied on "Blue-Green" deployments, where a new version of an application replaced the old one entirely after basic functional testing. However, machine learning models are probabilistic rather than deterministic, meaning they can be "code-complete" but "behaviorally flawed." This distinction has necessitated a more nuanced chronology of deployment:
- Offline Validation: Models are tested against historical data to ensure mathematical soundness.
- Infrastructure Verification: Ensuring the model can handle production request volumes and latency requirements.
- Controlled Exposure: Utilizing one or more of the four strategies to observe the model in a live environment.
- Full Promotion: The model becomes the primary system of record once statistical confidence is achieved.
Industry data from the 2024 State of MLOps report indicates that organizations utilizing these controlled strategies reduce their Mean Time to Recovery (MTTR) by nearly 60% compared to those using traditional "Big Bang" deployment methods.
A/B Testing: The Statistical Gold Standard
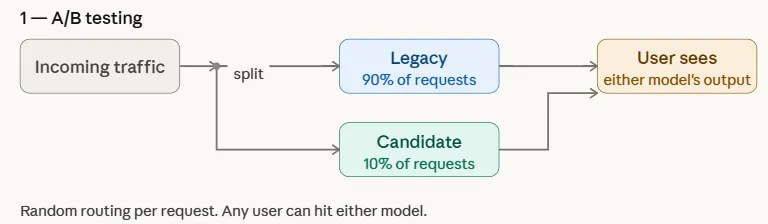
A/B testing remains the most prevalent strategy for evaluating the impact of a new ML model on business KPIs. In this framework, incoming production traffic is split between two versions of the system: the "Control" (the existing legacy model) and the "Variation" (the candidate model).
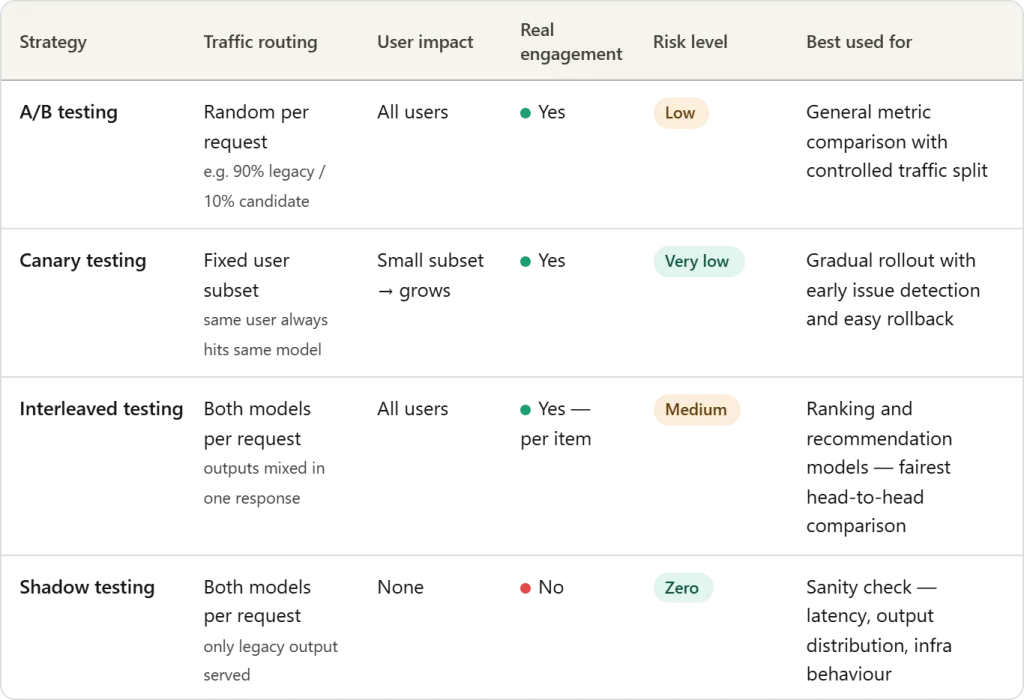
Technically, the split is often non-uniform during the early stages of a test. For instance, a team might route 95% of traffic to the legacy model and only 5% to the candidate model. This allows engineers to gather data on the candidate’s performance—such as click-through rates, conversion metrics, or revenue per user—without risking the experience of the entire user base.
The primary challenge of A/B testing in an ML context is achieving statistical significance. Depending on the volume of traffic and the expected "lift" in performance, an A/B test may need to run for days or weeks to ensure that the observed improvements are not due to random noise.
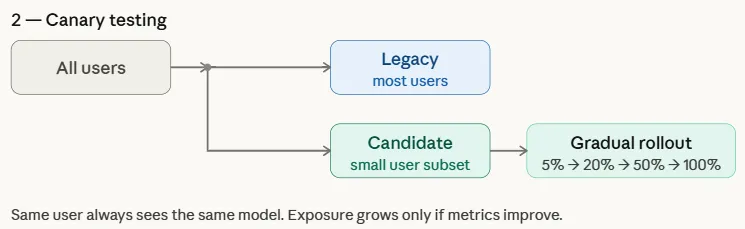
Canary Testing: Phased Rollouts for Risk Mitigation
Canary testing derives its name from the historical practice of using canary birds in coal mines to detect toxic gases. In the context of ML, the "canary" is a candidate model exposed to a small, specific subset of users before a wider release.
Unlike A/B testing, which focuses on comparing the business performance of two models, Canary testing is primarily concerned with operational stability and error detection. It is a phased approach where exposure is increased incrementally—moving from 1% to 5%, then 20%, and finally 100%—provided that system health metrics remain within acceptable thresholds.
If the canary model exhibits high latency, memory leaks, or a spike in error rates, the deployment is automatically rolled back. This strategy is particularly effective for large-scale distributed systems where a faulty model could otherwise lead to a total system outage.
Interleaved Testing: High-Precision Evaluation for Ranking Systems
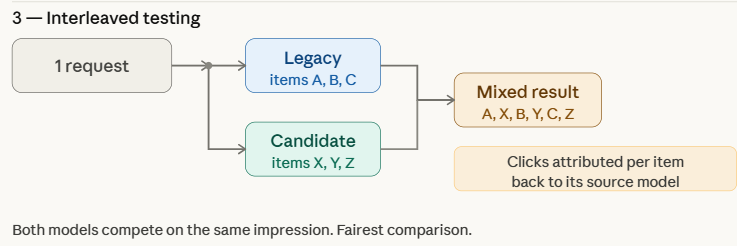
Interleaved testing is a specialized strategy most commonly used in recommendation engines and search systems. Instead of routing users to one model or another, the system combines the outputs of both the legacy and candidate models into a single response.
For example, in a streaming service’s recommendation list, the first item might be generated by the legacy model, the second by the candidate model, and so on. The system then tracks which items the user interacts with. Because both models are competing for the user’s attention within the exact same context and time frame, Interleaved testing eliminates many of the confounding variables—such as time of day or user demographic shifts—that can plague A/B tests.
Research from companies like Netflix suggests that Interleaved testing can identify a superior model with up to 100 times less data than a traditional A/B test, making it an invaluable tool for rapid experimentation in high-traffic environments.
Shadow Testing: The Zero-Risk Observation Deck
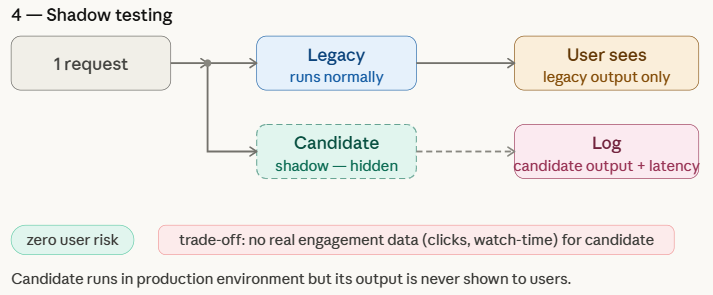
Shadow testing, or "Dark Launching," involves running a candidate model in parallel with the production model without ever showing its results to the user. Both models receive the same live input data, but only the legacy model’s output is served. The candidate model’s predictions are logged for retrospective analysis.
This strategy is the safest of the four because it has zero impact on the user experience. It allows engineers to:
- Benchmark Latency: Observe how the model performs under real production loads.
- Analyze Prediction Distribution: Ensure the new model’s outputs align with expected ranges.
- Verify Infrastructure: Confirm that the deployment pipeline and data features are functioning correctly in the live environment.
The limitation of shadow testing is its inability to measure user engagement metrics, such as clicks or conversions, as the user never interacts with the "shadowed" predictions.
Technical Simulation of Deployment Strategies
To illustrate the operational logic of these strategies, consider a Python-based simulation. This simulation uses a legacy_model and a candidate_model, where the candidate is intentionally designed to outperform the legacy version to verify the effectiveness of the testing strategies.
import random
import hashlib
random.seed(42)
def legacy_model(request):
# Simulates a legacy model with a maximum performance score of 0.35
return "model": "legacy", "score": random.random() * 0.35
def candidate_model(request):
# Simulates a candidate model with a maximum performance score of 0.55
return "model": "candidate", "score": random.random() * 0.55
def make_requests(n=200):
users = [f"user_i" for i in range(40)]
return ["id": f"req_i", "user": random.choice(users) for i in range(n)]
requests = make_requests()Simulating A/B Testing
In this A/B test simulation, 10% of traffic is routed to the candidate model. The average scores demonstrate the candidate’s superiority in a controlled split.
CANDIDATE_TRAFFIC = 0.10
def ab_route(request):
return candidate_model if random.random() < CANDIDATE_TRAFFIC else legacy_model
results = "legacy": [], "candidate": []
for req in requests:
model = ab_route(req)
pred = model(req)
results[pred["model"]].append(pred["score"])
for name, scores in results.items():
avg = sum(scores)/len(scores) if scores else 0
print(f"A/B Test - name:12s | requests: len(scores):3d | avg score: avg:.3f")Simulating Canary Testing
Canary testing uses deterministic hashing to ensure that specific users consistently see the same model, which is critical for maintaining a coherent user experience during a rollout.
def get_canary_users(all_users, fraction):
n = max(1, int(len(all_users) * fraction))
ranked = sorted(all_users, key=lambda u: hashlib.md5(u.encode()).hexdigest())
return set(ranked[:n])
all_users = list(set(r["user"] for r in requests))
for phase, fraction in [("Phase 1 (5%)", 0.05), ("Phase 2 (20%)", 0.20)]:
canary_users = get_canary_users(all_users, fraction)
# Logic for routing based on user ID...Industry Analysis and Broader Implications
The adoption of these strategies has profound implications for the reliability of AI systems. As regulatory bodies, such as the European Union through the AI Act, move toward stricter requirements for algorithmic transparency and robustness, controlled deployment becomes a matter of legal compliance as much as technical excellence.
Experts in the field argue that the "Model-Centric" era of AI is being replaced by a "System-Centric" era. In this new paradigm, the model is only as good as the deployment strategy that supports it. A failure to implement these safeguards can result in significant financial loss. For instance, in the broader software world, the 2012 Knight Capital Group incident—where a faulty deployment led to a $440 million loss in 45 minutes—serves as a perennial warning. While ML failures are often more subtle (e.g., biased recommendations or gradual revenue erosion), the cumulative impact can be equally devastating.
Furthermore, the rise of Large Language Models (LLMs) has introduced new complexities. Evaluating an LLM in production requires not just performance scores, but qualitative assessments of safety, hallucination rates, and toxicity. Companies are now adapting Canary and Shadow testing to include "LLM-as-a-judge" frameworks, where a secondary model audits the candidate model’s outputs in real-time.
In conclusion, the safe deployment of machine learning models is an iterative, multi-layered process. By leveraging A/B, Canary, Interleaved, and Shadow testing, organizations can bridge the gap between experimental success and production reliability, ensuring that AI remains a driver of value rather than a source of systemic risk.












