





The landscape of digital information retrieval is currently undergoing its most significant transformation since the inception of the World Wide Web. For nearly three decades, the industry standard for finding relevant documents within a database has been BM25, or Best Matching 25. This probabilistic rank function, which powers the search capabilities of ubiquitous platforms like Elasticsearch and Lucene, has long been the "gold standard" for keyword-based discovery. However, the recent explosion in Large Language Model (LLM) utility and the rise of Retrieval-Augmented Generation (RAG) have introduced a formidable alternative: dense vector search. While BM25 focuses on the literal occurrence of words, vector search attempts to map the underlying meaning and intent of a query, marking a shift from lexical matching to semantic understanding.
The Foundation of Modern Search: Understanding BM25
To appreciate the current shift in retrieval technology, one must first understand the mechanics of BM25. Developed in the 1970s and 1980s and finalized in the 1990s, BM25 is an evolution of the TF-IDF (Term Frequency-Inverse Document Frequency) model. It operates on a "bag-of-words" principle, treating documents as collections of tokens without regard for grammar or word order.
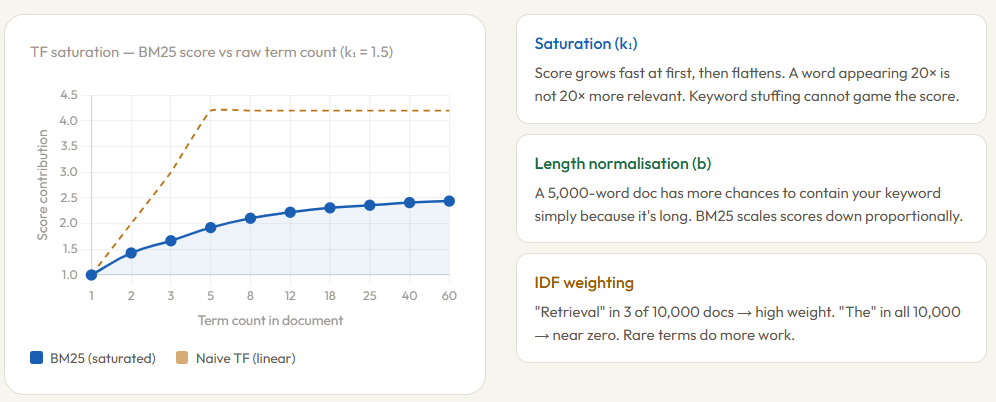
The algorithm calculates a relevance score based on three primary variables. First is Term Frequency (TF), which measures how often a query term appears in a specific document. Unlike its predecessors, BM25 employs "term frequency saturation." In practical terms, this means the algorithm recognizes that a word appearing 20 times in a document does not necessarily make that document 20 times more relevant than one where the word appears five times. The score plateaus, effectively neutralizing "keyword stuffing" tactics that once plagued early search engines. This behavior is governed by the parameter $k_1$, typically set between 1.2 and 2.0.
The second variable is Inverse Document Frequency (IDF), which penalizes common words like "the" or "and" while rewarding rare, highly descriptive terms. If a query includes the word "photosynthesis," BM25 recognizes that this term is rare across the entire corpus and gives it significant weight in the final ranking. Finally, the algorithm accounts for document length normalization. A longer document naturally has a higher probability of containing a query term simply by virtue of its size. The parameter $b$ (usually 0.75) penalizes longer documents to ensure that a concise, highly relevant article is not buried by a rambling, 100-page manual that happens to mention the keyword frequently.
The Chronology of Information Retrieval
The transition from keyword matching to semantic search did not happen overnight. The timeline of this evolution reflects the broader history of computational linguistics:
- 1970s: The introduction of TF-IDF provided the first mathematical framework for weighting the importance of words within a document relative to a corpus.
- 1994: Stephen E. Robertson and colleagues introduced the Okapi BM25 ranking function at City University London. It quickly became the dominant algorithm for the TREC (Text REtrieval Conference) competitions.
- 1999-2010: BM25 was integrated into major open-source search libraries, including Lucene, which later formed the basis for Elasticsearch and Solr.
- 2013: Google researchers released Word2Vec, demonstrating that words could be represented as dense vectors in a continuous space, where words with similar meanings were positioned close to one another.
- 2018: The release of BERT (Bidirectional Encoder Representations from Transformers) by Google revolutionized the field by providing context-aware embeddings, allowing models to understand that the "bank" in "river bank" is different from the "bank" in "investment bank."
- 2022-Present: The mainstreaming of RAG systems has made vector search a requirement for developers looking to connect LLMs to private, proprietary data.
The Shift to Semantic Vector Search
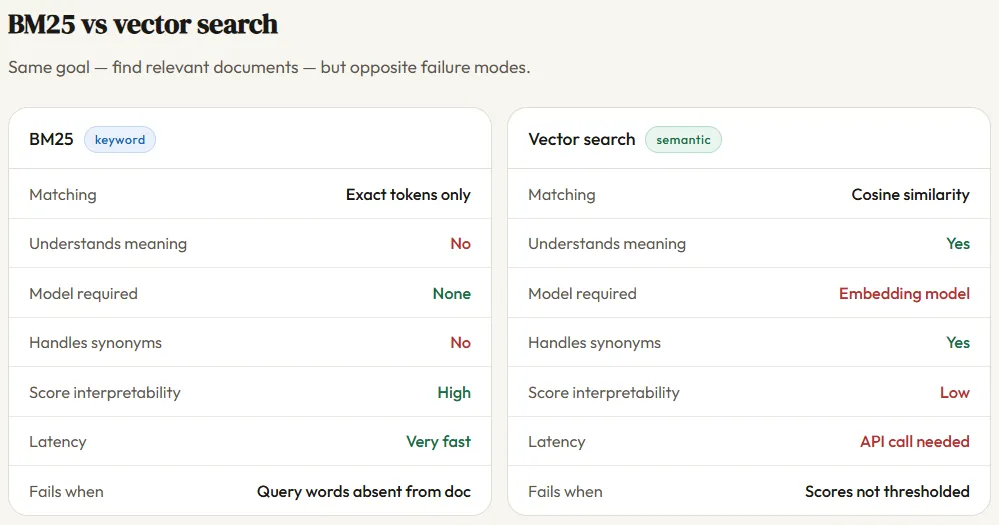
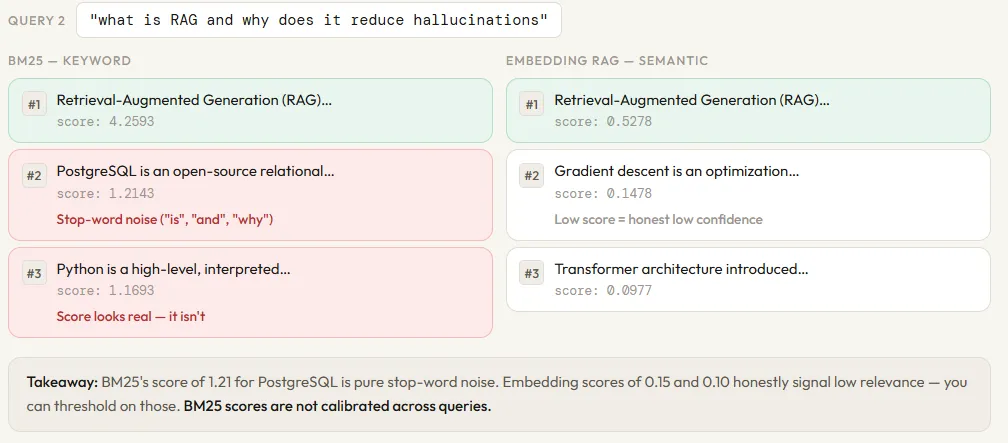
While BM25 is efficient and explainable, it suffers from a "vocabulary mismatch" problem. If a user searches for "feline healthcare" and a document only contains the phrase "cat wellness," BM25 will fail to find a match. This limitation is the primary driver behind the adoption of vector search in RAG pipelines.
Vector search utilizes embedding models—such as OpenAI’s text-embedding-3-small or open-source alternatives like Hugging Face’s BGE models—to convert text into high-dimensional numerical arrays. In this vector space, "feline" and "cat" are mathematically similar. When a query is issued, the system performs a "nearest neighbor" search, typically using cosine similarity to find the documents whose vectors point in the most similar direction as the query vector.
This approach allows for a level of nuance previously impossible. Vector search can handle synonyms, paraphrasing, and even cross-lingual retrieval. However, it is not without its drawbacks. Vector search is computationally expensive, requiring GPUs for embedding generation and specialized vector databases (like Pinecone, Milvus, or Weaviate) for storage and retrieval. Furthermore, vector search can sometimes "hallucinate" relevance by focusing too much on general themes and missing specific, rare keywords or technical serial numbers that BM25 would catch instantly.
Technical Demonstration: Implementing a Comparative System in Python
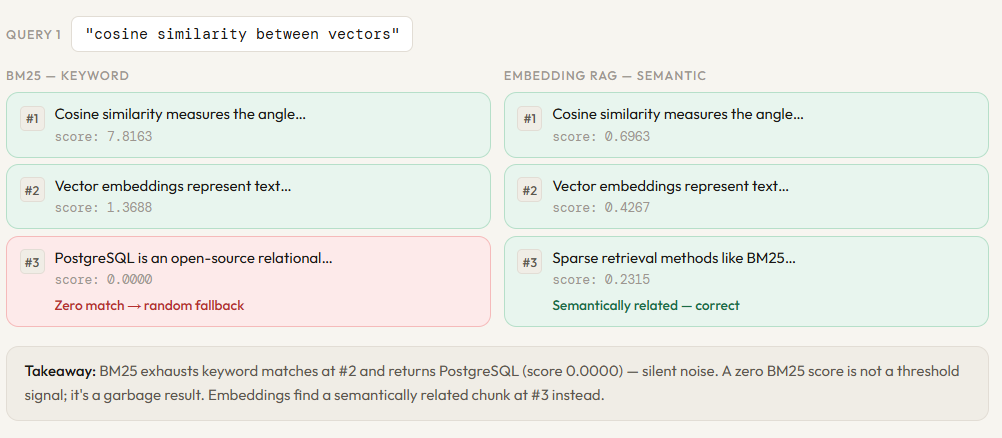
To illustrate these differences, developers often utilize Python-based simulations. By constructing a small corpus of 12 distinct chunks—ranging from descriptions of Python web frameworks like Django to database systems like PostgreSQL—one can observe the divergent behaviors of these two retrieval methods.
In a typical implementation, the BM25 retriever is built using the rank_bm25 library. The process involves tokenizing the corpus (lowercasing and splitting into individual words) and calculating the IDF scores. The search function then produces a relevance score for each chunk based on lexical overlap.
Conversely, the embedding retriever requires an API integration, such as OpenAI. Each of the 12 chunks is sent to an embedding model, which returns a 1,536-dimensional vector. These vectors are stored in memory. At query time, the user’s query is also embedded, and a dot product calculation determines the cosine similarity.

When tested with a query like "how does BM25 rank documents," both systems typically perform well because the query contains the specific term "BM25." However, when the query is shifted to something more conceptual, such as "techniques for finding similar content without exact word overlap," BM25 often fails to return a result, whereas the vector search successfully identifies chunks related to "vector embeddings" and "semantic search."
Supporting Data: Performance and Cost Trade-offs
The choice between BM25 and vector search often comes down to the specific requirements of the application. Data from recent industry benchmarks highlights the following trade-offs:
- Latency: BM25 is nearly instantaneous, often returning results in under 10 milliseconds for moderately sized collections. Vector search involves an embedding step (which can take 100-500ms depending on the API or local model) plus the search time.
- Infrastructure Cost: BM25 is CPU-bound and requires minimal memory. Vector search requires significant RAM to store dense vectors and often necessitates expensive GPU resources for real-time embedding.
- Explainability: BM25 provides a transparent score. A developer can see exactly which word contributed to a document’s rank. Vector search is a "black box"; it is often difficult to explain why the model determined that two vectors were similar.
- Accuracy on Out-of-Distribution Data: BM25 is robust across different domains. Vector search is highly dependent on the data the embedding model was trained on. If a model was trained on general web text, it may struggle with highly specialized medical or legal jargon.
Industry Responses and the Rise of Hybrid Search
The consensus among major tech firms and search engineers is that neither algorithm is a "silver bullet." In response, the industry has moved toward "Hybrid Search." Platforms like Elasticsearch and various vector database providers now offer a combined approach that runs BM25 and vector search in parallel.
The results are then merged using a technique called Reciprocal Rank Fusion (RRF). RRF provides a way to combine the rankings from different retrieval methods without needing to normalize their underlying scores (which are calculated on entirely different scales). This ensures that if a document is ranked highly by either BM25 (due to a rare keyword match) or vector search (due to semantic relevance), it will appear at the top of the final results list.
Statements from engineering teams at companies like Microsoft and Amazon suggest that hybrid search provides a 15% to 20% increase in retrieval accuracy over using either method in isolation. This "best of both worlds" approach is currently the production standard for enterprise-grade RAG systems.
Broader Impact and Future Implications
The implications of this technological tug-of-war extend far beyond simple search bars. In the context of RAG, the quality of retrieval directly dictates the quality of the LLM’s output. If the retriever fails to find the correct context, the LLM is forced to rely on its internal training data, leading to the "hallucinations" that plague modern AI applications.
As we look toward the future, the boundary between keyword and semantic search continues to blur. New "sparse embedding" models aim to provide the benefits of vector search while maintaining the efficiency and keyword-sensitivity of BM25. Furthermore, the development of "ColBERT" (Contextualized Late Interaction over BERT) represents a new frontier, allowing for a more granular interaction between query terms and document terms than traditional single-vector embeddings.
Ultimately, the evolution from BM25 to vector search—and the eventual synthesis into hybrid systems—represents a fundamental shift in how humans interact with machines. We are moving away from a world where we must speak the language of the computer (keywords) and toward a world where the computer understands the language of the human (intent and meaning). For developers and enterprises, the challenge lies not in choosing one over the other, but in mastering the orchestration of both to build truly intelligent information systems.











