




While the rapid advancement of large vision-language models has dominated the artificial intelligence landscape over the past two years, the integration of complex audio reasoning has remained a significant hurdle for researchers. While models like GPT-4V and LLaVA have demonstrated remarkable proficiency in interpreting visual data, the ability to robustly reason over speech, environmental acoustics, and music—particularly in long-form recordings—has lagged. This gap in multimodal AI is now being addressed by a collaborative effort between NVIDIA and researchers from the University of Maryland. The team has officially announced the release of Audio Flamingo Next (AF-Next), a powerful and fully open Large Audio-Language Model (LALM) designed to set a new standard for open-source audio intelligence.
The introduction of AF-Next represents a major milestone in the "Audio Flamingo" series, which has evolved through several iterations to refine how machines perceive and interpret sound. Unlike previous models that were often limited to short clips or specific types of audio, AF-Next is trained on internet-scale data, encompassing approximately 108 million samples and one million hours of audio. This scale allows the model to handle diverse tasks ranging from simple transcription to complex, multi-step reasoning over long-form audio files spanning up to 30 minutes.
Defining the Large Audio-Language Model Landscape
A Large Audio-Language Model (LALM) is a specialized multimodal architecture that pairs a sophisticated audio encoder with a decoder-only language model. This configuration enables the system to perform tasks such as question answering, captioning, and reasoning directly from audio inputs. While standard Large Language Models (LLMs) process text, and Vision-Language Models (VLMs) process images, LALMs are designed to treat audio as a primary input modality, effectively bridging the gap between raw sound waves and human-like linguistic understanding.
The release of AF-Next includes three specialized variants tailored for specific industrial and research applications. The first, AF-Next-Instruct, is optimized for general-purpose interaction and question-answering. The second, AF-Next-Think, utilizes advanced reasoning capabilities to solve complex problems through multi-step logic. The third, AF-Next-Captioner, is dedicated to generating highly detailed descriptions of audio environments, identifying everything from background noises to the subtle nuances of musical compositions.

Architectural Innovations and the AF-Whisper Encoder
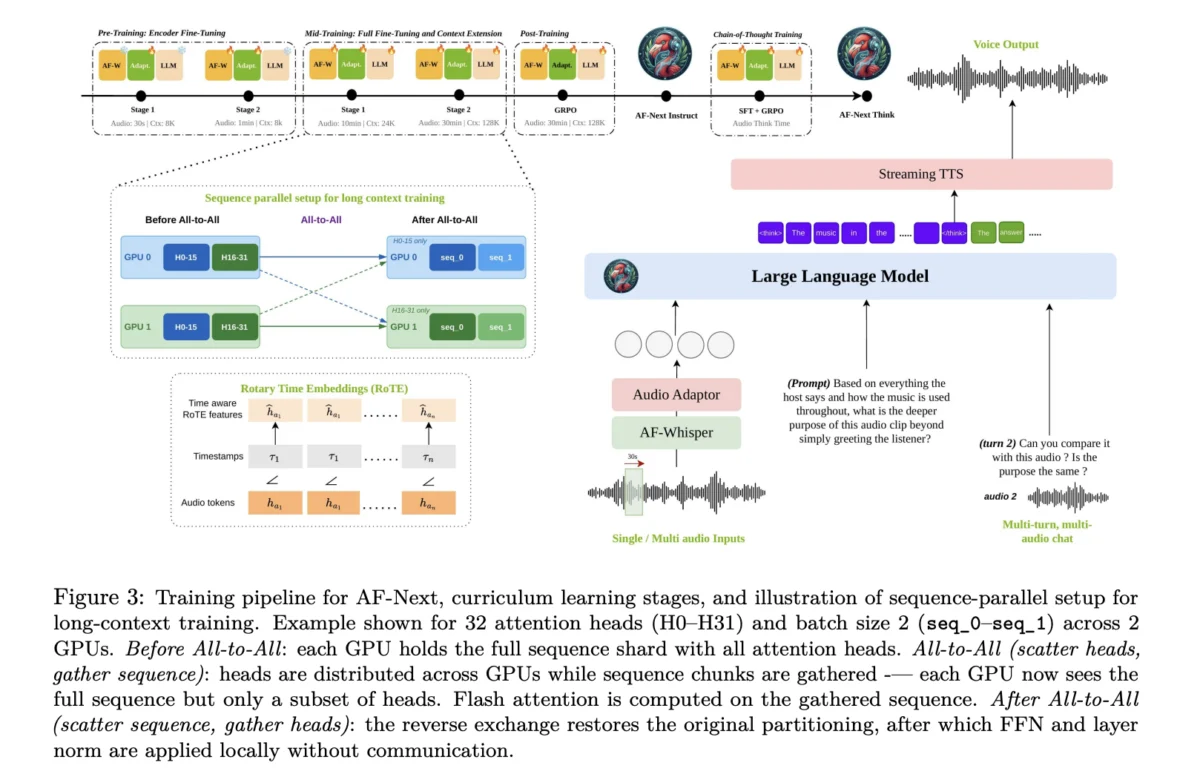
At the heart of AF-Next lies a sophisticated four-component pipeline designed to process audio with high fidelity. The first component is the AF-Whisper audio encoder. Building upon the foundations of OpenAI’s Whisper, the NVIDIA and Maryland team further pre-trained this encoder on a massive corpus that includes multilingual speech and multi-talker Automatic Speech Recognition (ASR) data. When an audio signal is fed into the system, it is resampled to 16 kHz mono and converted into a 128-channel log mel-spectrogram. This spectrogram is processed in 30-second non-overlapping chunks, allowing the model to maintain clarity even in dense audio environments.
The second component is a two-layer Multi-Layer Perceptron (MLP) audio adaptor. This serves as the bridge between the audio encoder and the language model, mapping the audio representations into the language model’s embedding space. The third component, the LLM backbone, is based on Qwen-2.5-7B. This decoder-only causal model features 7 billion parameters and 36 transformer layers. Notably, the researchers extended the context length of this backbone from 32,000 to 128,000 tokens, a necessary adjustment to accommodate the data-heavy nature of long-form audio.
One of the most significant technical breakthroughs in AF-Next is the implementation of Rotary Time Embeddings (RoTE). Traditional transformers use positional encodings that index tokens by their sequence position. However, for audio, the actual timestamp is often more relevant than the sequence number. RoTE replaces standard positional rotations with a system grounded in absolute timestamps. This allows the model to perform precise temporal reasoning, enabling it to pinpoint exactly when a specific sound occurs within a 30-minute recording—a feat that has historically challenged multimodal models.
Temporal Audio Chain-of-Thought Reasoning
Reasoning over audio requires more than just identifying sounds; it requires understanding the context and sequence of events. To improve performance in this area, the researchers introduced "Temporal Audio Chain-of-Thought" (CoT). While CoT has been successful in text-based models, its application in audio has been limited by a lack of high-quality training data.
To overcome this, the team developed AF-Think-Time, a dataset comprising 43,000 training samples curated from complex sources such as movie trailers, mystery stories, and long-form multi-party conversations. In this framework, the model is trained to anchor every intermediate reasoning step to a specific timestamp. By forcing the model to "think" about when an event happened before providing a final answer, the researchers have significantly reduced hallucinations and improved the model’s ability to aggregate evidence over long durations.
A Four-Stage Training Curriculum at Internet Scale
Training a model of this magnitude required a massive computational effort and a structured pedagogical approach. The training process for AF-Next followed a four-stage curriculum:
- Pre-training: This stage focused on the audio adaptor and the audio encoder. Initially, the LLM remained frozen while the system learned to map short 30-second audio clips to the embedding space.
- Mid-training: The entire model was fine-tuned using the AudioSkills-XL dataset. During this phase, the audio length was increased to 10 minutes, and the context window was expanded to 24,000 tokens. The AF-Next-Captioner variant is the direct result of this stage.
- Post-training: The researchers applied Group Relative Policy Optimization (GRPO)-based reinforcement learning. This stage focused on multi-turn chat capabilities, safety protocols, and instruction following, resulting in the AF-Next-Instruct variant.
- CoT-training: The final stage involved Supervised Fine-Tuning (SFT) on the AF-Think-Time dataset. By applying GRPO to the post-training mixture, the team produced AF-Next-Think, the most reasoning-capable model in the suite.
To make the training of 128,000-token context windows feasible, the team employed a hybrid sequence parallelism strategy. This involved combining "Ulysses attention" (for efficient intra-node communication) with "Ring attention" (for scaling across multiple nodes). This technical infrastructure prevented the quadratic memory costs of self-attention from becoming a bottleneck during the processing of long audio files.
Performance Benchmarks and Comparative Analysis
The results of the AF-Next deployment have been verified across several industry-standard benchmarks, where the model consistently outperformed both its predecessors and prominent closed-source competitors.
On the MMAU-v05.15.25 benchmark—the most widely recognized metric for audio reasoning—AF-Next-Instruct achieved an average accuracy of 74.20. The AF-Next-Think variant reached 75.01, while the Captioner variant pushed the score to 75.76. These figures represent a significant jump over Audio Flamingo 3’s 72.42. In the more rigorous MMAU-Pro benchmark, AF-Next-Think scored 58.7, surpassing the 57.4 score of Google’s closed-source Gemini-2.5-Pro.
The model’s superiority is particularly evident in long-audio understanding. On LongAudioBench, AF-Next-Instruct achieved a score of 73.9, dwarfing Gemini 2.5 Pro’s 60.4. In speech-inclusive tests, AF-Next reached 81.2, compared to Gemini’s 66.2. Furthermore, the model set new records for Automatic Speech Recognition (ASR) with a Word Error Rate (WER) of just 1.54 on the LibriSpeech test-clean dataset.
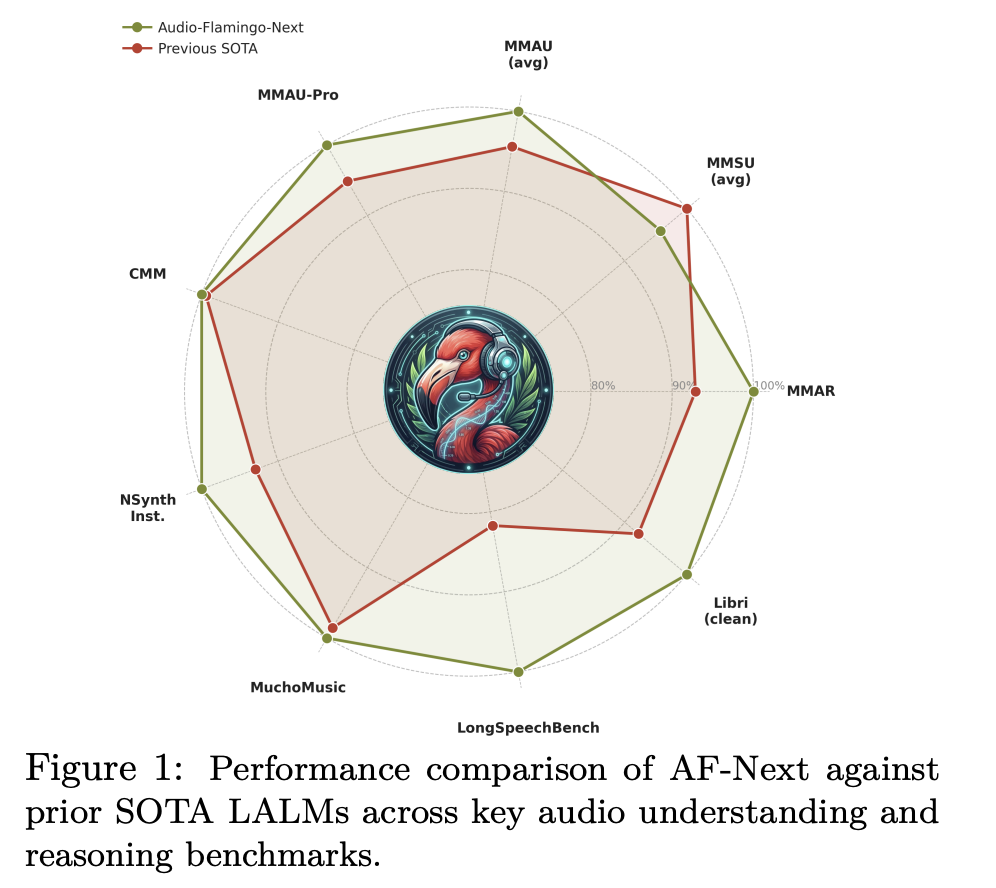
Music understanding also saw a dramatic improvement. On the Medley-Solos-DB instrument recognition test, AF-Next reached an accuracy of 92.13%, a substantial increase from the 85.80% seen in Audio Flamingo 2. In music captioning, GPT-5 based evaluations of coverage and correctness rose to 8.8 and 8.9 respectively, indicating a high level of descriptive accuracy.
Broader Impact and Industry Implications
The release of Audio Flamingo Next by NVIDIA and the University of Maryland has profound implications for the future of AI development. By making the model fully open—including weights and training methodologies—the researchers are democratizing access to high-tier audio intelligence.
In the consumer sector, this technology could lead to more responsive and context-aware voice assistants that can understand not just what a user says, but the environment they are in (e.g., recognizing the sound of a boiling pot or a crying baby). In the media and entertainment industry, AF-Next-Captioner could automate the generation of descriptive audio for the visually impaired with unprecedented detail.
Furthermore, the model’s ability to handle multi-talker environments and identify interruptions makes it a potent tool for corporate applications, such as automated meeting transcription and analysis. The significant improvements in speech translation—specifically the 12-point jump in Arabic-to-English translation over previous models—suggest that AF-Next will be a critical asset for global communication platforms.
As AI continues to move toward a truly multimodal future, the success of AF-Next demonstrates that audio is no longer a "lagging frontier." Through innovative architectural choices like RoTE and hybrid sequence parallelism, and the curation of massive, high-quality datasets, the barrier between sound and sense is rapidly dissolving. The collaboration between industry leader NVIDIA and the academic prowess of the University of Maryland has provided the research community with a powerful new toolset to explore the complexities of the acoustic world.












