




The landscape of enterprise artificial intelligence shifted significantly today as Cohere, a prominent developer of large language models (LLMs) and embedding technology, officially announced its entry into the Automatic Speech Recognition (ASR) sector. With the release of Cohere Transcribe, the Toronto-based company aims to resolve a persistent bottleneck in corporate data processing: the conversion of unstructured audio into high-fidelity, actionable text. Traditionally, enterprises have relied on complex, multi-stage pipelines or proprietary APIs that often struggle with technical jargon, varied accents, and long-form recordings. Cohere Transcribe seeks to simplify this infrastructure by offering a high-performance, open-weight alternative designed specifically for production environments.
The launch marks a strategic expansion for Cohere, which has built its reputation on text-generation models like Command and its industry-leading embedding and Rerank models. By integrating ASR into its ecosystem, Cohere is positioning itself to provide a comprehensive end-to-end solution for "Speech-to-Action" workflows, where audio data is not just transcribed but immediately made available for downstream tasks such as summarization, sentiment analysis, and retrieval-augmented generation (RAG).
The Evolution of Speech Architecture: The Conformer Advantage
To achieve competitive accuracy, Cohere has moved beyond the standard Transformer-only architectures that have dominated the field in recent years. Cohere Transcribe utilizes an encoder-decoder framework featuring a large Conformer encoder paired with a lightweight Transformer decoder. This hybrid approach represents a significant technical milestone in ASR development.
The Conformer architecture was designed to address the specific limitations of earlier models. In speech recognition, the system must process two distinct types of information. First, it must identify local features, such as specific phonemes, rapid transitions in sound, and the nuances of individual speakers. Convolutional Neural Networks (CNNs) are historically superior at capturing these fine-grained acoustic details. Second, the model must understand the global context—the overarching meaning of a sentence—to distinguish between homophones (e.g., "their" vs. "there") based on syntax. Transformers excel at these long-range dependencies.
By interleaving CNN and Transformer layers within the encoder, Cohere Transcribe captures both local and global signals simultaneously. The model was trained using standard supervised cross-entropy, a robust objective function that prioritizes the minimization of discrepancies between the predicted text and ground-truth transcripts. This technical foundation allows the model to maintain high accuracy even in the presence of background noise or complex terminology common in professional settings.
Performance Benchmarks and Industry Standing
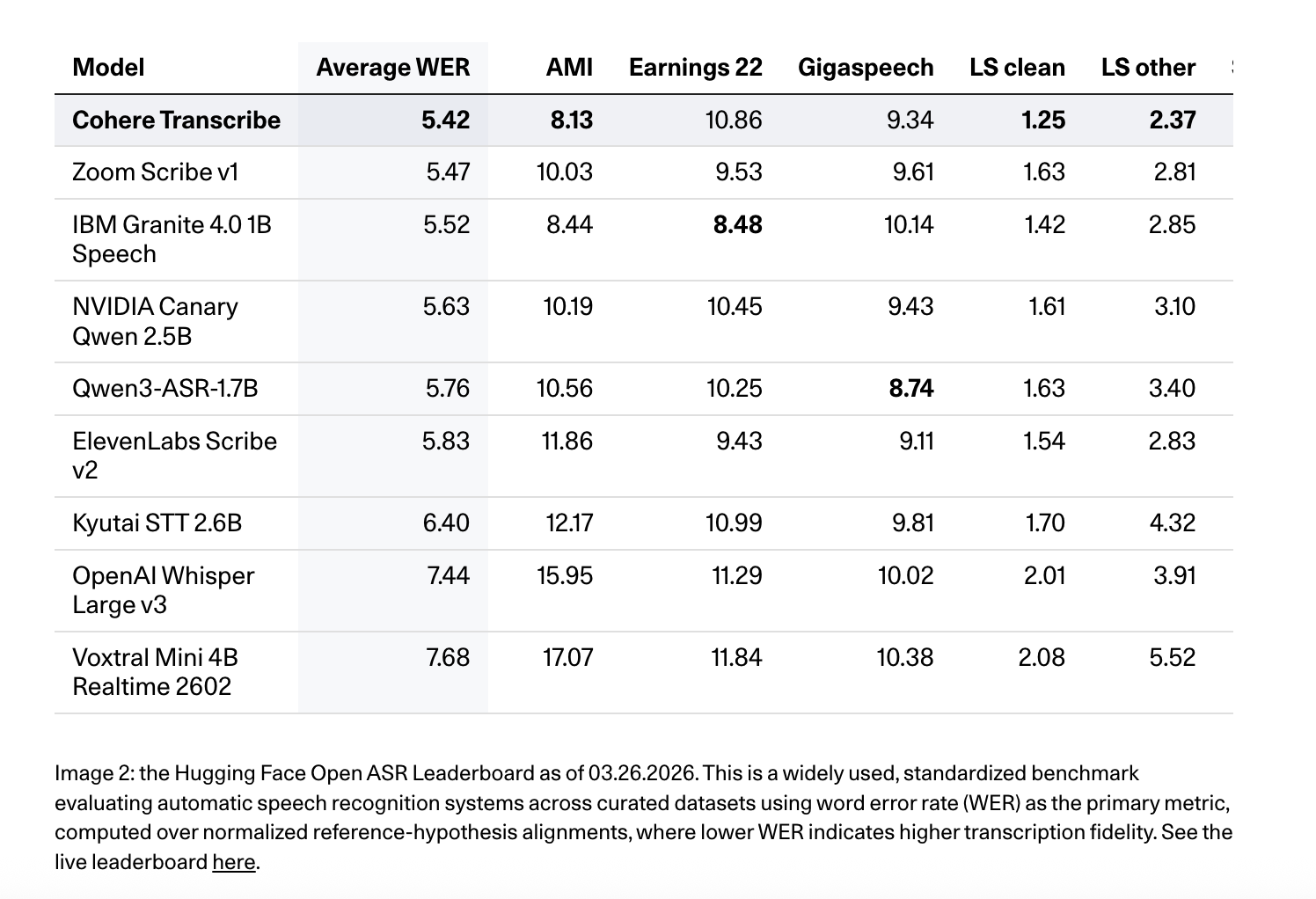
Upon its release, Cohere Transcribe has claimed the top position on the Hugging Face Open ASR Leaderboard, a key industry metric for evaluating speech models. As of March 26, 2026, the model achieved an average Word Error Rate (WER) of 5.42% across a diverse battery of benchmark datasets. This performance places it ahead of several established competitors, including OpenAI’s Whisper Large v3, which holds an average WER of 7.44%, and ElevenLabs Scribe v2, which sits at 5.83%.

The model’s performance across specific datasets highlights its versatility in different audio environments:
- LibriSpeech (Clean/Other): The model recorded a WER of 1.25 on "clean" speech and 2.37 on "other," demonstrating its ability to handle both high-quality recordings and more challenging, noisy audio.
- Earnings22: On this dataset, which consists of complex financial earnings calls filled with industry-specific jargon and diverse accents, the model achieved a WER of 10.86%.
- TED-LIUM: For presentation-style speech, the model scored a 2.49% WER.
- AMI and GigaSpeech: The model recorded scores of 8.13 and 9.34, respectively, outperforming Qwen3-ASR-1.7B in these categories.
Beyond raw metrics, Cohere emphasized the importance of "human preference" in transcription quality. While WER measures literal accuracy, it does not always capture the readability or formatting nuances that humans value. In head-to-head comparisons conducted by human annotators, Cohere Transcribe was preferred 78% of the time over IBM Granite 4.0 1B Speech and 64% of the time over Whisper Large v3. This suggests that the model is particularly adept at producing transcripts that feel natural and require less manual post-editing.
Strategic Focus: Quality Over Quantity in Language Support
In a departure from competitors who aim to support hundreds of languages with varying levels of reliability, Cohere has adopted a "quality over quantity" strategy. At launch, Cohere Transcribe officially supports 14 languages: English, German, French, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Arabic, Vietnamese, Chinese, Japanese, and Korean.
These languages represent the vast majority of global business transactions and data generation. By narrowing the scope, Cohere has been able to fine-tune the model for high-accuracy performance in each supported tongue, ensuring that the model meets the rigorous standards of enterprise use cases such as legal discovery, medical transcription, and international financial reporting.
Solving the Long-Form Audio Dilemma: The 35-Second Rule
One of the primary technical hurdles in ASR is the processing of long-form audio. Standard neural networks are often limited by memory constraints, making it difficult to process an hour-long recording in a single pass without exhausting GPU VRAM. Cohere addresses this through a sophisticated chunking and reassembly logic.
The model is natively designed to process audio in 35-second segments. For files exceeding this duration—such as a 60-minute boardroom meeting or a legal deposition—the system automatically segments the audio. The engineering pipeline handles the orchestration of these chunks, ensuring that the transitions between segments are seamless and that the final transcript maintains linguistic coherence. This approach allows enterprises to scale their transcription efforts without requiring specialized high-memory hardware, making the model more accessible for deployment in various cloud and on-premise environments.
Chronology of Development and Market Context
The release of Cohere Transcribe comes at a time when the demand for "multimodal" AI is peaking. For the past three years, the industry has moved from text-only models to systems that can see, hear, and speak. Cohere’s timeline reflects this evolution:
- 2023-2024: Cohere solidifies its position in the enterprise market with Command R and R+, focusing on RAG and tool-use capabilities.
- Late 2025: Internal development of ASR technology begins, aiming to remove the reliance on third-party transcription services for Cohere’s enterprise clients.
- March 2026: Official release of Cohere Transcribe and the publication of model weights on Hugging Face.
The decision to release the model weights on Hugging Face is a significant move toward transparency and developer adoption. It allows organizations to host the model on their own infrastructure, ensuring data privacy—a critical requirement for sectors like healthcare and defense.
Industry Implications and Future Outlook
The introduction of a high-performance, enterprise-ready ASR model by a company of Cohere’s stature is likely to have several long-term effects on the AI market. First, it intensifies the competition with OpenAI and NVIDIA. While OpenAI’s Whisper has been the "de facto" standard for open-source ASR, Cohere’s superior performance on the Hugging Face leaderboard suggests a shifting of the guard.
Second, this launch facilitates the rise of "Audio RAG." Currently, most RAG systems only "search" through text documents. With highly accurate transcription, companies can now index their entire history of meetings, phone calls, and video presentations, making that knowledge searchable and actionable.
Analysts suggest that Cohere’s move is part of a broader trend toward vertical integration in AI. By owning the transcription layer (ASR), the embedding layer (Embed), and the reasoning layer (Command), Cohere provides a unified stack that reduces latency and cost for its customers.
As enterprises continue to move AI projects from experimental labs to production environments, the demand for reliable "plumbing"—the tools that convert raw data into usable formats—will only grow. Cohere Transcribe represents a significant step forward in making audio data as accessible and useful as text, potentially unlocking thousands of hours of untapped corporate intelligence.
The model weights and technical documentation are currently available for the developer community on Hugging Face under the Cohere Labs repository, signaling a new chapter in the company’s mission to power the next generation of business intelligence.












