





The introduction of TRIBE v2 aims to bridge this gap by leveraging the power of tri-modal foundation models. By aligning the latent representations of state-of-the-art artificial intelligence architectures with human brain activity, the FAIR team has created a system capable of predicting high-resolution functional Magnetic Resonance Imaging (fMRI) responses across a diverse array of naturalistic and experimental conditions. This development marks a pivotal shift toward "in-silico neuroscience," where AI models serve as digital proxies for the human brain, allowing researchers to conduct virtual experiments and pilot studies with unprecedented scale and precision.
The Architecture of Multi-modal Integration
At its core, TRIBE v2 is built upon the principle of representational alignment. The model does not attempt to learn how to process visual or auditory information from scratch; instead, it utilizes the pre-existing capabilities of frozen foundation models that have already been trained on massive datasets. The architecture is composed of three primary stages: specialized feature extractors, a temporal transformer, and a subject-specific prediction block.
The stimulus processing phase employs three specialized encoders to handle different streams of information. For visual stimuli, the model utilizes high-performance computer vision architectures to extract spatial and semantic features from video frames. Auditory information is processed through acoustic encoders that capture the nuances of sound, from simple tones to complex speech patterns. Language, perhaps the most complex human faculty, is handled by large language model (LLM) components that decode the symbolic and contextual meaning of text.
Once these features are extracted, they are compressed into a shared latent dimension of $D=384$. These embeddings are then concatenated to form a multi-modal time series with a model dimension of $D_model = 1152$. This integrated sequence is fed into a Transformer encoder, featuring 8 layers and 8 attention heads. This specific configuration allows the model to exchange information across a 100-second temporal window, reflecting the brain’s ability to maintain context and integrate information over time.

The final stage involves subject-specific prediction. Because fMRI data is typically recorded at a lower temporal resolution than AI model processing, the Transformer’s outputs are decimated to match the 1 Hz fMRI frequency. These representations are then passed through a "Subject Block," which projects the latent data onto 20,484 cortical vertices and 8,802 subcortical voxels. This allows TRIBE v2 to predict activity not just in broad regions, but at a high-resolution level across the entire brain structure.
Overcoming Data Scarcity through Scaling Laws
One of the primary obstacles in the field of brain encoding has been the scarcity of high-quality neuroimaging data. Collecting fMRI scans is an expensive and time-consuming process, often resulting in datasets that are either "deep" (many hours of data from a few subjects) or "wide" (limited data from many subjects). TRIBE v2 addresses this challenge by strategically utilizing both types of data.
During the training phase, the FAIR team utilized "deep" datasets, allowing the model to learn the intricate relationship between stimuli and neural responses from individuals who had undergone extensive scanning. For evaluation, "wide" datasets were used to test the model’s ability to generalize across a broader population.
A critical finding of the Meta research team is the existence of log-linear scaling laws within brain encoding. Their analysis revealed that encoding accuracy increases consistently as the volume of training data grows, with no immediate evidence of a performance plateau. This suggests that the predictive power of models like TRIBE v2 is currently limited only by the size of available neuroimaging repositories. As global efforts to share and aggregate brain data expand, the accuracy of these AI-driven "digital brains" is expected to see corresponding improvements.
Benchmarking Performance and Zero-Shot Generalization
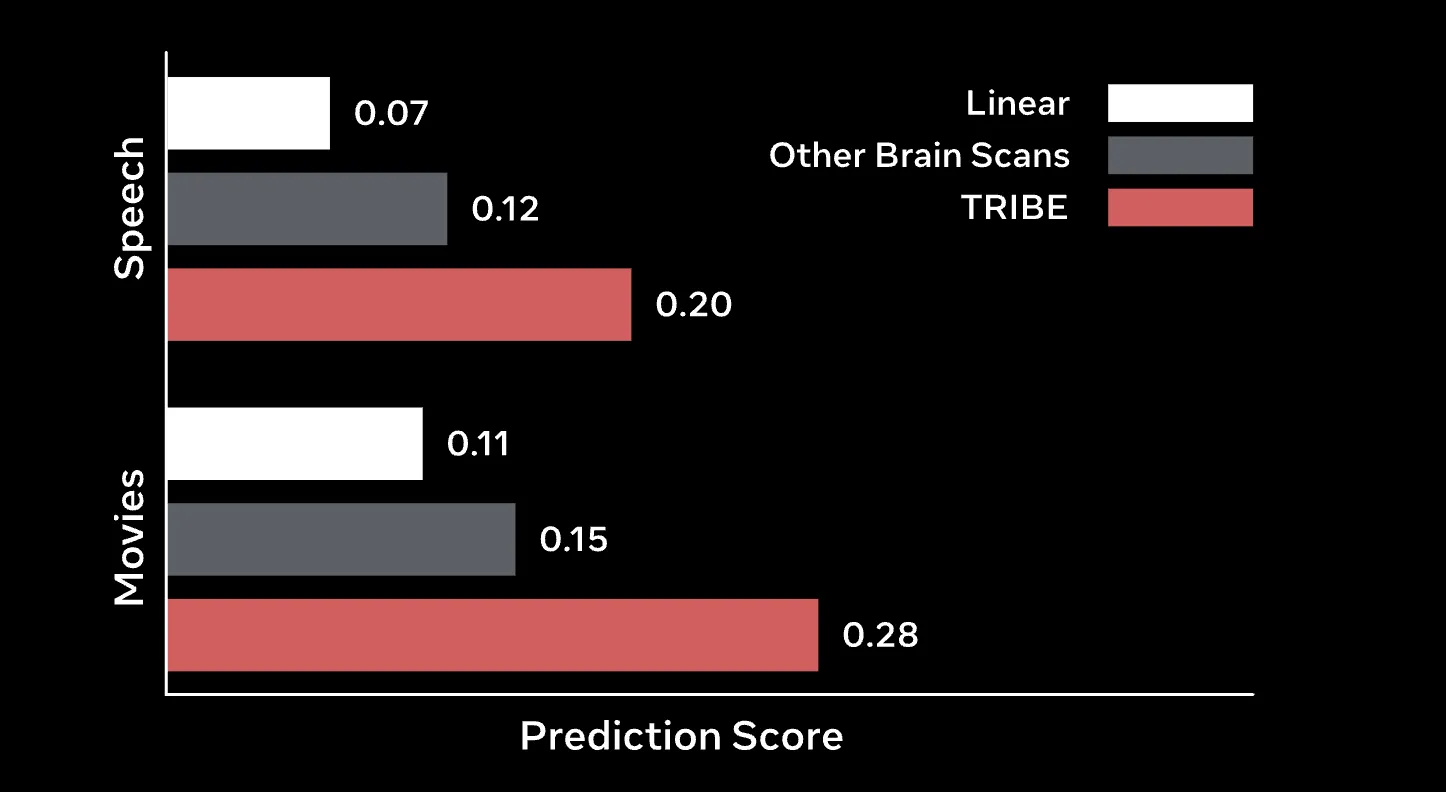
In rigorous testing, TRIBE v2 demonstrated a significant performance advantage over traditional Finite Impulse Response (FIR) models. For years, FIR models have been the gold standard for voxel-wise encoding, yet they often struggle to capture the non-linear complexities of multisensory integration. TRIBE v2 not only outperformed these baselines in standard predictive tasks but also exhibited remarkable "zero-shot" capabilities.

Zero-shot generalization refers to the model’s ability to predict the brain activity of a new subject without having been trained on that specific individual’s data. By employing an "unseen subject" layer, TRIBE v2 can predict the group-averaged response of a new cohort with higher accuracy than the actual recordings of many individual subjects within that same cohort. In tests using the high-resolution Human Connectome Project (HCP) 7T dataset, the model achieved a group correlation near 0.4. This represents a two-fold improvement over the median subject’s group-predictivity, highlighting the model’s capacity to capture the universal underlying patterns of human neural processing.
Furthermore, the model showed exceptional efficiency when fine-tuned. When provided with as little as one hour of data from a new participant, a single epoch of fine-tuning TRIBE v2 resulted in a two- to four-fold improvement in accuracy compared to linear models trained from scratch. This efficiency makes TRIBE v2 a highly practical tool for clinical and research settings where scanning time is limited.
In-Silico Experimentation and Functional Landmarks
The utility of TRIBE v2 extends beyond simple prediction; it serves as a powerful tool for virtual neuroscience. The FAIR team conducted "in-silico" experiments using the Individual Brain Charting (IBC) dataset to determine if the model could independently recover established functional landmarks. The results were highly encouraging.
Without being explicitly programmed to find them, TRIBE v2 successfully identified classic brain regions such as the Visual Word Form Area (VWFA), which is essential for reading, and the Extrastriate Body Area (EBA), which responds to human body parts. Moreover, by applying Independent Component Analysis (ICA) to the model’s final layer, the researchers discovered that TRIBE v2 naturally organized itself into five well-known functional networks:
- Primary Auditory Network: Processing basic sound stimuli.
- Language Network: Managing syntax and semantics.
- Motion Network: Detecting movement in the visual field.
- Default Mode Network: Active during internal thought and rest.
- Visual Network: Handling complex image and video processing.
This emergence of biological organization within a synthetic model provides strong evidence that the representations learned by modern AI architectures are fundamentally aligned with the organizational principles of the human cortex.
Broader Implications and Future Directions
The release of TRIBE v2 carries profound implications for both the fields of AI development and neuroscience. By providing a unified, tri-modal foundation model, Meta has offered a roadmap for moving away from fragmented, region-specific studies toward a holistic understanding of the "active" brain in natural environments.
In the medical field, TRIBE v2 could revolutionize the way we approach neurodegenerative diseases and brain injuries. If a model can accurately predict what a "healthy" brain response should look like for a given stimulus, it can be used as a diagnostic benchmark to identify deviations caused by pathology. Additionally, the model’s high-resolution predictions could assist in the development of more sophisticated Brain-Computer Interfaces (BCIs), potentially allowing for more seamless communication for individuals with motor impairments.
From an AI perspective, the success of TRIBE v2 reinforces the "Scaling Hypothesis"—the idea that more data and more compute lead to qualitatively better models. It also suggests that the path to Artificial General Intelligence (AGI) may involve models that are increasingly "human-like" in their internal representations, as the alignment between TRIBE v2 and the human brain suggests a convergence of biological and artificial processing strategies.
However, the advancement of brain-encoding technology also raises important ethical considerations. As models become more adept at decoding neural activity into text, images, or intent, the issue of "neural privacy" becomes paramount. Ensuring that these technologies are used to empower individuals rather than monitor them will be a critical challenge for policymakers and technologists alike.
Meta has made the code, weights, and a demo for TRIBE v2 publicly available, encouraging the global research community to build upon this foundation. This open-science approach is likely to accelerate the integration of AI and neuroscience, paving the way for a new era of discovery where the mysteries of human consciousness are explored through the lens of computational intelligence. As neuroimaging data continues to grow in volume and complexity, TRIBE v2 stands as a testament to the transformative potential of multi-modal AI in unlocking the secrets of the most complex structure in the known universe: the human brain.












