The persistent challenge of the "black box" nature of deep learning has long hindered the adoption of artificial intelligence in high-stakes environments where transparency and accountability are paramount. While neural networks have achieved unprecedented success in tasks ranging from natural language processing to scientific discovery, the internal logic of these models—comprising millions or billions of parameters—remains largely indecipherable to human observers. To address this fundamental limitation, a research team from the University of Cambridge has introduced SymTorch, an open-source library designed to bridge the gap between connectionist architecture and symbolic logic. By integrating symbolic regression directly into the PyTorch ecosystem, SymTorch allows developers to approximate complex neural network components with closed-form mathematical expressions, potentially transforming opaque models into human-readable equations.
The Evolution of Interpretability in Machine Learning
The quest for interpretable machine learning has historically followed two distinct paths. On one side are "white box" models, such as linear regression and decision trees, which are inherently understandable but often lack the representational power to handle complex, high-dimensional data. On the other side are "black box" models, primarily deep neural networks, which offer immense predictive power at the cost of interpretability. Previous attempts to explain these complex models have often relied on post-hoc methods like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations). While useful, these methods provide local approximations or importance scores rather than a global, functional understanding of the model’s logic.
Symbolic regression (SR) represents a third way. Unlike standard regression, which optimizes coefficients for a pre-defined functional form, SR searches the space of mathematical expressions to find the equation that best fits the data. This approach can discover fundamental laws of nature or simplified logic that a neural network has implicitly learned during training. However, implementing SR within modern deep learning workflows has traditionally been a fragmented and engineering-intensive process. SymTorch aims to standardize this process, providing a seamless interface that treats symbolic approximation as a first-class citizen within the PyTorch framework.
The Technical Architecture: The Wrap-Distill-Switch Workflow
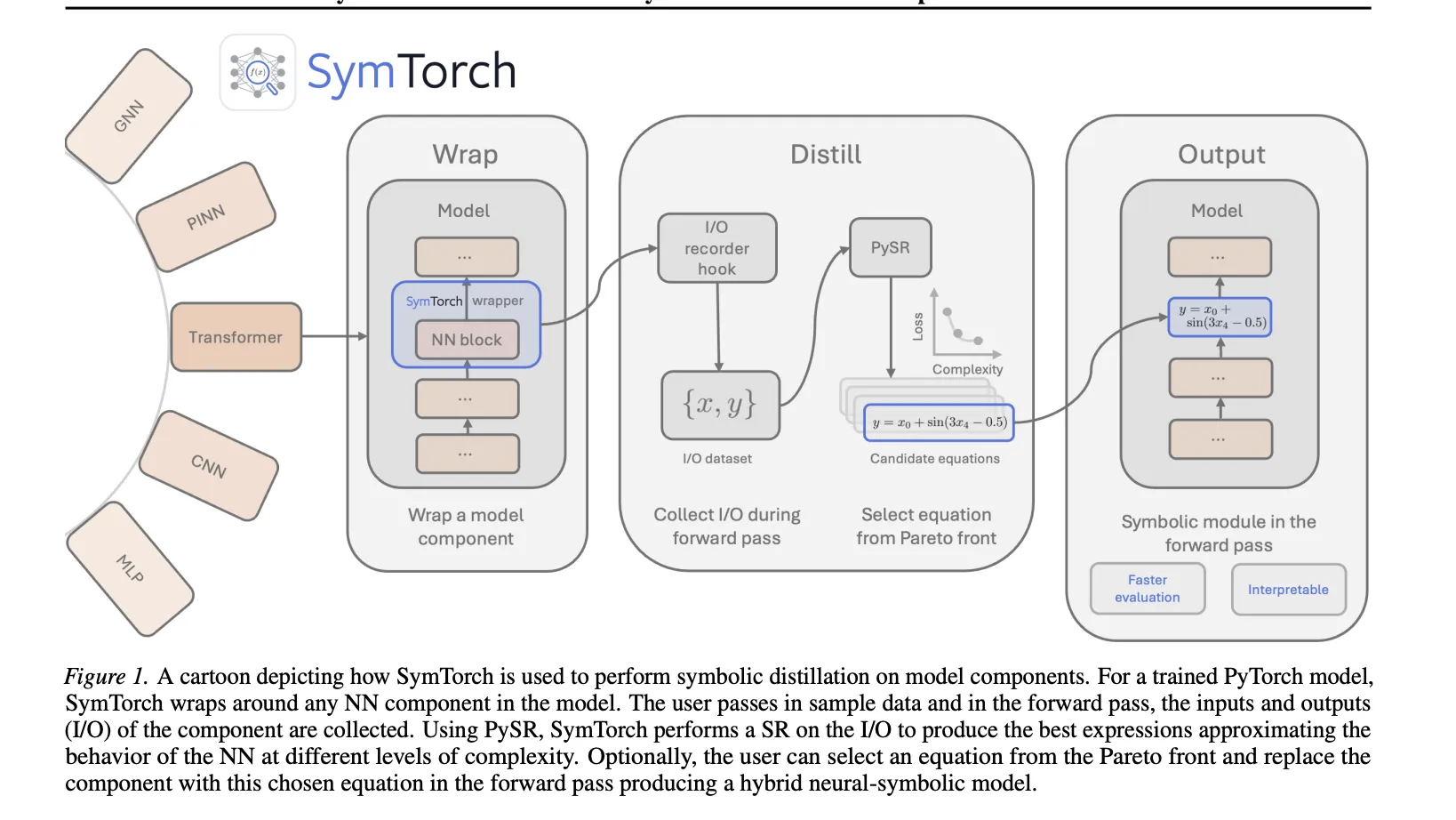
SymTorch introduces a structured three-stage methodology known as "Wrap-Distill-Switch." This framework is designed to minimize the friction of extracting symbolic representations from existing, pre-trained models.
The "Wrap" phase involves identifying specific modules within a neural network—such as a single layer, a block of layers, or an entire sub-network—and wrapping them with SymTorch hooks. These hooks are designed to intercept the input and output tensors during a forward pass without altering the model’s underlying behavior. This non-invasive approach allows researchers to target specific "bottlenecks" or layers of interest within a massive architecture.
In the "Distill" phase, the library collects a representative dataset of inputs and corresponding outputs from the wrapped modules as the model processes a calibration dataset. This data serves as the ground truth for the symbolic regression engine. SymTorch interfaces directly with PySR, a high-performance symbolic regression backend that utilizes a multi-population genetic algorithm. The algorithm evolves a population of mathematical expressions, testing various combinations of operators (addition, multiplication, sine, cosine, etc.) to find the most accurate and parsimonious fit.

The final "Switch" phase is where the symbolic approximation is reintegrated into the model. Once an optimal equation is found, SymTorch allows the user to replace the original neural network module with a "Symbolic Layer." This replacement can be used for two primary purposes: functional interpretability, where the researcher analyzes the equation to understand the model’s logic, and inference acceleration, where the mathematical equation is executed in place of computationally expensive matrix multiplications.
Balancing Complexity and Accuracy: The Pareto Front
A core component of the SymTorch methodology is the use of a Pareto front to select the "best" symbolic equation. In the context of symbolic regression, there is an inherent trade-off between the complexity of an equation (the number of operators and constants it contains) and its accuracy (how closely it matches the neural network’s output).
PySR and SymTorch evaluate candidate equations based on these two conflicting objectives. The Pareto front represents the set of non-dominated solutions—equations for which no other equation is both simpler and more accurate. To automate the selection process, the researchers employ a scoring metric that identifies the equation at the "elbow" of the Pareto curve. This is typically the point where the fractional drop in log mean absolute error is maximized relative to an increase in complexity. By selecting equations at this juncture, SymTorch ensures that the resulting mathematical expressions are simple enough for human interpretation while maintaining high fidelity to the original neural network’s behavior.
Case Study: Accelerating Large Language Model Inference
One of the most compelling applications of SymTorch demonstrated by the Cambridge team involves the optimization of Large Language Models (LLMs). Specifically, the researchers targeted the Multi-Layer Perceptron (MLP) layers within the Transformer architecture. In many modern LLMs, MLP layers account for a significant portion of the total computational budget during inference.
For their experiment, the team utilized the Qwen2.5-1.5B model. Due to the high dimensionality of LLM activations, performing symbolic regression directly on the raw data would be computationally prohibitive. To mitigate this, the researchers employed Principal Component Analysis (PCA) as a pre-processing step. They compressed the input and output dimensions of three targeted MLP layers, selecting 32 principal components for the inputs and 8 for the outputs.
The results of this intervention were significant. By replacing the dense MLP layers with symbolic surrogates, the researchers achieved an 8.3% increase in token throughput. The average latency per request dropped from 209.89 ms in the baseline model to 193.89 ms in the symbolically augmented version. However, this gain in efficiency came with a trade-off in model performance. The perplexity on the Wikitext-2 dataset rose from 10.62 to 13.76. Crucially, the researchers noted that this increase in error was primarily driven by the information loss during PCA dimensionality reduction rather than the symbolic approximation itself, suggesting that further refinements in compression techniques could narrow the performance gap.
Scientific Discovery and Physics-Informed Models
Beyond the optimization of LLMs, SymTorch shows immense promise in the field of scientific machine learning. The researchers validated the library’s utility by applying it to Graph Neural Networks (GNNs) and Physics-Informed Neural Networks (PINNs) trained on physical systems.
In scientific modeling, neural networks are often used to learn the dynamics of complex systems where the underlying governing equations are unknown or partially understood. By applying SymTorch to the latent representations of these models, the researchers were able to recover known physical laws, such as Newtonian gravitational formulas and planetary motion equations, directly from the data-driven models. This capability is vital for "AI for Science," as it allows researchers to verify that a model has learned physically consistent representations rather than merely overfitting to noise or spurious correlations.
Chronology and Development Context
The release of SymTorch (early 2026) follows a period of intense scrutiny regarding AI safety and the "right to explanation" enshrined in various regulatory frameworks, such as the EU AI Act. The development timeline of SymTorch reflects a broader shift in the AI research community:
- 2020-2023: Explosion of Large Language Models and "black box" AI, leading to increased calls for transparency.
- 2024: Rise of Symbolic Regression tools like PySR, which demonstrated the ability to distill knowledge from data into equations but remained difficult to integrate with deep learning.
- 2025: Research begins at the University of Cambridge (AstroAutomata group) to create a unified bridge between PyTorch and SR engines.
- 2026: Official release of SymTorch, accompanied by the paper detailing the Wrap-Distill-Switch workflow and its application to Transformer architectures.
Broader Impact and Industry Implications
The implications of SymTorch extend far beyond academic research. In industries such as finance, healthcare, and aerospace, the inability to explain a model’s decision can be a deal-breaker. A symbolic equation providing a clear relationship between input variables and an output prediction offers a level of auditability that matrix weights cannot match.
Furthermore, the inference acceleration aspect of SymTorch addresses the growing demand for "Green AI." As the energy consumption of data centers continues to climb, replacing power-hungry neural network layers with efficient mathematical approximations could provide a pathway toward more sustainable AI deployments. While the current trade-off between accuracy and speed is still being optimized, SymTorch provides the foundational tooling necessary for the industry to explore these hybrid architectures.
The library is currently available on GitHub, and the research team has invited the broader machine learning community to contribute to its development. By making symbolic regression an accessible part of the deep learning toolkit, SymTorch represents a significant step toward a future where artificial intelligence is not just powerful, but also understandable and verifiable.