



Tencent AI Lab has announced the official release of Covo-Audio, a sophisticated 7-billion-parameter end-to-end Large Audio Language Model (LALM) designed to bridge the gap between complex linguistic reasoning and raw acoustic processing. By integrating speech processing and language intelligence into a unified architectural framework, Covo-Audio marks a significant departure from traditional cascaded systems that rely on separate modules for Automatic Speech Recognition (ASR), Large Language Models (LLMs), and Text-to-Speech (TTS) synthesis. This release represents a strategic move by Tencent to advance the frontier of multimodal AI, offering a model that can directly process continuous audio inputs and generate high-fidelity audio outputs within a single, cohesive neural network.
The development of Covo-Audio comes at a time when the global AI research community is pivoting toward "omni" models—systems capable of perceiving and generating multiple data modalities simultaneously. Unlike previous generations of audio-capable AI, which often lost nuances like emotion, tone, and prosody during the conversion from speech to text, Covo-Audio maintains the integrity of the acoustic signal. This allows for a more "human-like" interaction, where the model can understand not just what is being said, but how it is being delivered.
The Architecture of Multimodal Integration
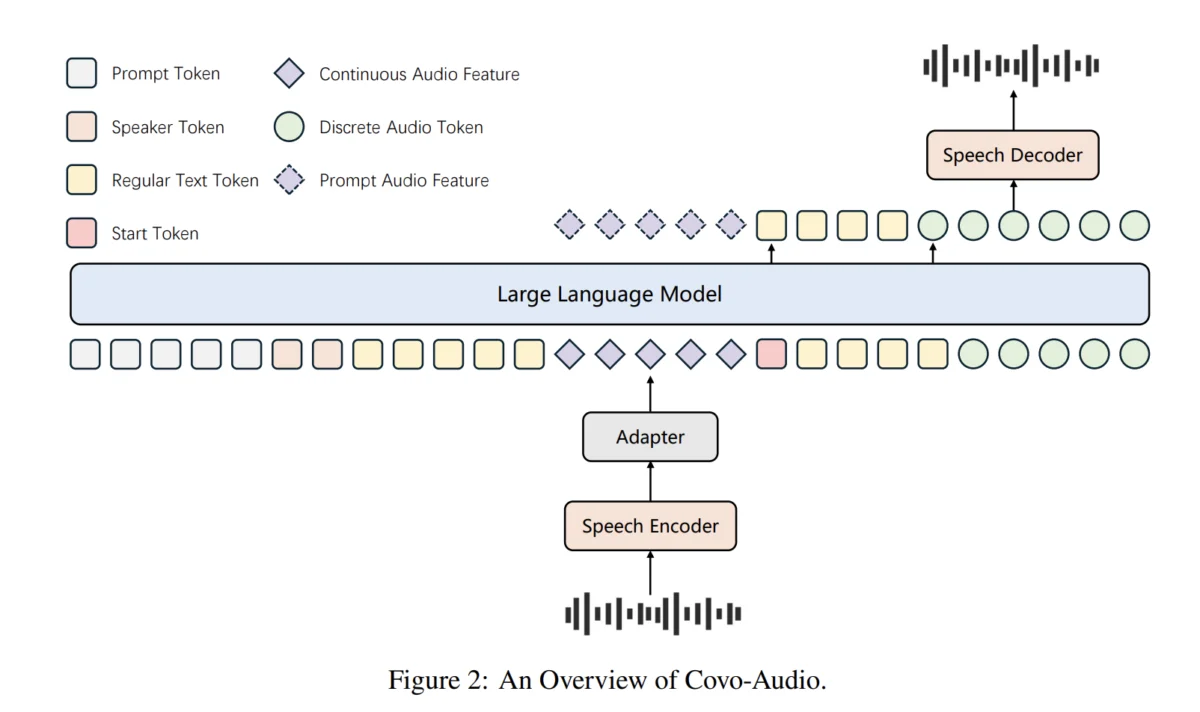
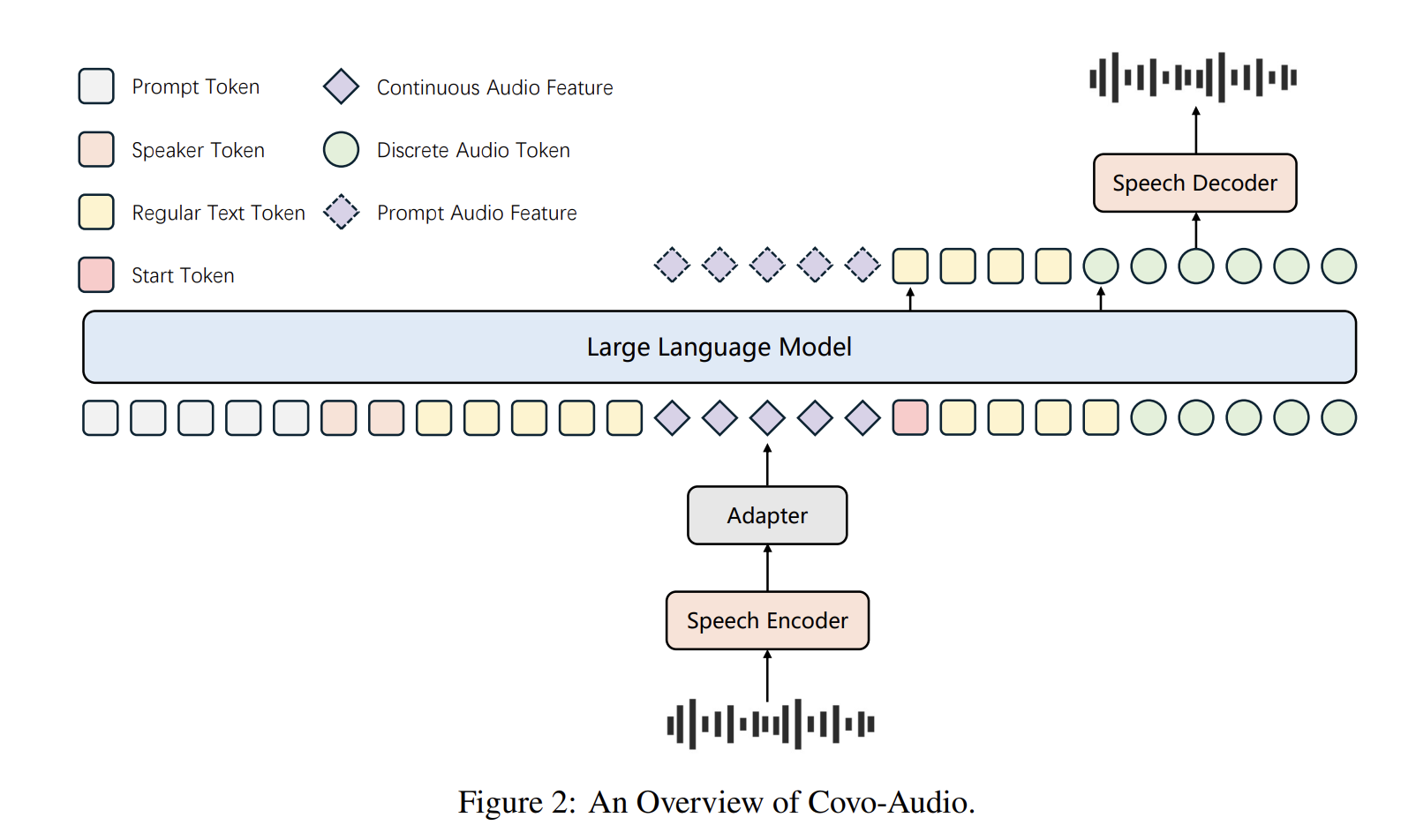
The Covo-Audio framework is built upon four primary pillars designed to facilitate seamless cross-modal interaction. At its core, the system utilizes a high-performance Audio Encoder, which translates raw sound waves into a dense representation that the model can interpret. This is followed by a specialized Bridge module, which acts as a translator between the acoustic space and the linguistic space, ensuring that the features extracted from the audio are compatible with the model’s internal reasoning engine.
The third component is the 7B-parameter Large Language Model (LLM) backbone. This serves as the "brain" of the system, responsible for high-level reasoning, context management, and decision-making. Finally, the Audio Decoder converts the model’s internal representations back into audible speech. By training these components in an end-to-end fashion, Tencent AI Lab has minimized the latency and information loss typically associated with multi-stage audio processing pipelines.
A distinguishing technical achievement of this project is the implementation of Hierarchical Tri-modal Speech-Text Interleaving. While standard models often struggle to align audio signals with text at a granular level, Covo-Audio utilizes a strategy that synchronizes three distinct data types: continuous acoustic features ($a_c$), discrete speech tokens ($a_d$), and natural language text ($t$). This hierarchy operates on two levels: phrase-level interleaving for fine-grained alignment and sentence-level interleaving to preserve the global semantic integrity of long-form speech. This dual-layered approach ensures that the model remains coherent even during extended monologues or complex multi-turn dialogues.
Intelligence-Speaker Decoupling and Customization
One of the most significant challenges in developing conversational AI is the high cost of data acquisition. Creating high-quality, speaker-specific dialogue datasets requires thousands of hours of recorded conversation, which is often prohibitively expensive. To circumvent this, the Tencent research team introduced a novel "Intelligence-Speaker Decoupling" strategy. This technique allows the model to separate its reasoning capabilities from its voice rendering characteristics.
By utilizing high-quality TTS recordings reformatted into "pseudo-conversations" with masked text loss, the model can learn to emulate a specific voice without needing to see that speaker engage in complex reasoning tasks. This decoupling means that Covo-Audio can inherit the naturalness and personality of a specific speaker using minimal data, while still utilizing its full 7B-parameter intelligence to formulate responses. This has profound implications for the development of personalized digital assistants, allowing users to interact with AI that sounds like a specific individual without compromising the AI’s cognitive performance.
Advancing to Full-Duplex Voice Interaction
To push the boundaries of real-time utility, Tencent evolved the base model into Covo-Audio-Chat-FD, a variant specifically optimized for full-duplex communication. In traditional "half-duplex" AI interactions, the user speaks, the model processes, and then the model responds—much like a walkie-talkie. Full-duplex communication, however, allows for simultaneous dual-stream interaction, enabling the AI to listen and speak at the same time, much like a natural human conversation.
The Covo-Audio-Chat-FD variant achieves this by reformatting the audio encoder into a chunk-streaming architecture. User and model audio streams are interleaved in a 1:4 ratio, with each chunk representing a mere 0.16 seconds of audio. This high-frequency interleaving allows the model to respond almost instantaneously to interruptions or changes in the user’s speech.
The system manages these complex conversational states through a set of specialized architectural tokens:
- VAD (Voice Activity Detection) Tokens: Used to identify whether the user is speaking or silent.
- EOU (End of Utterance) Tokens: Signal when the user has finished their thought.
- Response/Thinking Tokens: Manage the transition between internal reasoning and external speech generation.
For multi-turn scenarios, the model implements a recursive context-filling strategy. This ensures that continuous audio features from previous turns are preserved as historical context, allowing the AI to remember the emotional tone and specific details of an ongoing conversation.
Reasoning and Reinforcement Learning
Beyond mere conversation, Covo-Audio is designed for complex reasoning. The research team integrated Chain-of-Thought (CoT) processing, a technique that allows the model to "think out loud" before arriving at a conclusion. To optimize this process, Tencent employed Group Relative Policy Optimization (GRPO), a reinforcement learning technique that fine-tunes the model based on a verifiable composite reward function.
The reward function, $R_total$, is calculated as the sum of four critical metrics:
- $R_accuracy$: Measuring the factual correctness of the response.
- $R_format$: Ensuring the output adheres to the required structural constraints.
- $R_consistency$: Verifying that the logical flow remains sound throughout the interaction.
- $R_thinking$: Rewarding the model for demonstrating depth and nuance in its reasoning process.
This rigorous optimization process ensures that Covo-Audio is not just a "chatbot" but a reasoning engine capable of solving mathematical problems, explaining scientific concepts, and navigating complex social cues through voice interaction.
Benchmark Performance and Comparative Analysis
The efficacy of Covo-Audio has been validated through extensive testing on several industry-standard benchmarks. In the MMAU (Multimodal Audio Understanding) benchmark, the 7B-parameter model achieved an average score of 75.30%, the highest recorded for a model of its scale. It demonstrated particular strength in music understanding, scoring 76.05%, which highlights its ability to process non-speech acoustic data with high precision.
On the MMSU (Massive Multimodal Speech Understanding) benchmark, Covo-Audio maintained its lead with a 66.64% average accuracy. In the realm of spoken dialogue, the Covo-Audio-Chat variant outperformed competitors such as Qwen3-Omni on the Chinese track of the URO-Bench. Furthermore, the model set new standards for empathetic interaction on the VStyle benchmark, achieving state-of-the-art results in Mandarin for expressing complex emotions such as anger (4.89), sadness (4.93), and anxiety (5.00) on a five-point scale.
However, the research team also identified areas for improvement. During testing on the GaokaoEval full-duplex setting, researchers noted an "early-response" issue. This phenomenon occurs when unusually long silent pauses in the user’s speech cause the model to trigger a response prematurely. This behavior is currently a primary focus for the team’s future optimization efforts, as refining the model’s understanding of silence is as crucial as its understanding of sound.
Broader Impact and Industry Implications
The release of Covo-Audio as an open-source project—with weights available on Hugging Face and code on GitHub—is a significant event for the AI ecosystem. By providing the global research community with a high-performance, 7B-parameter LALM, Tencent is lowering the barrier to entry for developers looking to build sophisticated voice-first applications.
The potential applications for Covo-Audio are vast. In the healthcare sector, the model could power empathetic virtual health assistants capable of detecting distress in a patient’s voice. In education, it could provide real-time, interactive tutoring that adapts to a student’s level of confusion or engagement. In the automotive industry, full-duplex interaction could lead to safer, more intuitive in-car voice commands that feel like talking to a human co-pilot.
Furthermore, Covo-Audio’s ability to handle 2 trillion tokens during its two-stage pre-training pipeline demonstrates the massive scale of data required to achieve this level of multimodal fluency. This highlights the ongoing "arms race" in AI development, where data curation and architectural innovation are equally vital.
As Tencent AI Lab continues to iterate on the Covo-Audio framework, the focus will likely shift toward reducing the computational footprint of the model to allow for on-device deployment. If successful, this could bring the power of full-duplex, reasoning-capable AI to smartphones and IoT devices, fundamentally changing how humans interact with the digital world. For now, Covo-Audio stands as a testament to the rapid convergence of audio processing and large-scale language intelligence.











