

The landscape of modern software engineering is increasingly defined by the efficiency of asynchronous processing, a paradigm that allows applications to remain responsive while handling resource-intensive operations in the background. While enterprise-level solutions like Celery and Redis have long dominated this space, a growing movement toward minimalist, "zero-dependency" infrastructure has brought lighter alternatives into the spotlight. Among these, Huey—a versatile task queue for Python—is gaining traction for its ability to provide production-grade features such as retries, scheduling, and task prioritization without the operational overhead of a dedicated in-memory data store like Redis.
By utilizing SQLite as a backend, developers can now implement robust background processing systems that are entirely self-contained within a single database file. This architecture is particularly advantageous for cloud notebook environments, edge computing, and small-to-medium-scale web applications where simplicity and cost-efficiency are paramount. The following report details the technical implementation and strategic implications of deploying a Huey-SQLite task management system.
The Shift Toward Minimalist Asynchronous Architectures
For years, the standard recommendation for Python developers requiring background tasks was a combination of Celery and Redis. While powerful, this stack introduces significant complexity: Redis requires its own server instance, maintenance, and monitoring, while Celery’s configuration can be daunting for smaller projects.
Huey, developed by Charles Leifer, offers a middle ground. It provides a familiar API for defining tasks and periodic jobs but supports a SQLite backend. SQLite’s Write-Ahead Logging (WAL) mode allows for concurrent reads and writes, making it a viable queueing mechanism for many workloads. The transition toward SQLite-backed queues represents a broader industry trend known as "The Small File Revolution," where developers prioritize portability and reduced "moving parts" in their infrastructure.
Technical Framework and Implementation Chronology
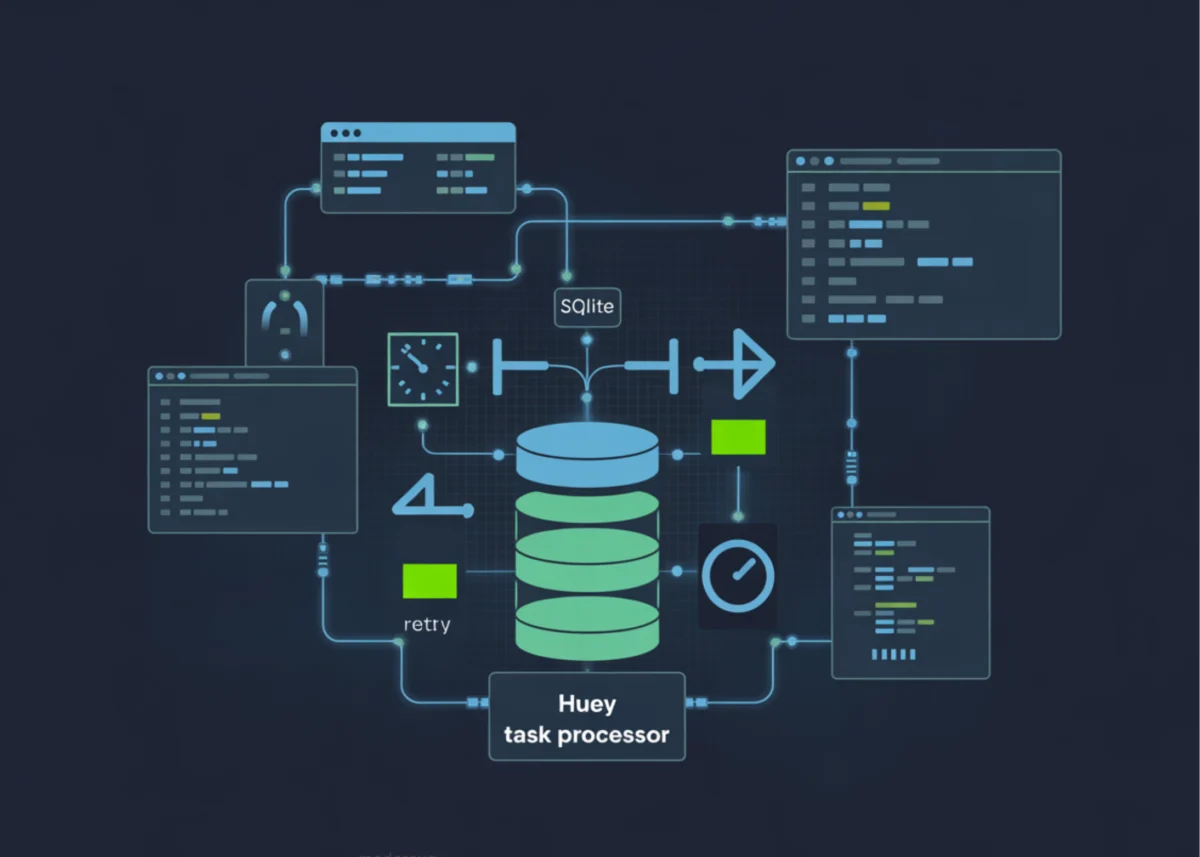
The construction of a SQLite-backed Huey system follows a logical progression from environment configuration to the orchestration of complex task workflows. Unlike Redis-based systems, the setup process begins with the initialization of a local database file, which serves as the central nervous system for all task enqueuing and results storage.
1. Environment Configuration and Initialization
The first phase involves the installation of the Huey library and the configuration of the SqliteHuey instance. In a typical deployment, the system is initialized by specifying a database path and enabling results storage. This step is critical as it establishes the persistence layer; if the consumer crashes, the tasks remain safely stored in the SQLite file, ready for recovery upon restart.
In a production-style simulation, developers often remove existing database files to ensure a clean state, followed by the instantiation of the Huey object with specific parameters:
- Name: A unique identifier for the queue.
- Filename: The path to the SQLite database.
- UTC: Ensuring all timestamps are synchronized to Coordinated Universal Time to avoid scheduling conflicts across different time zones.
2. Observability through Signal Integration
A significant challenge in distributed systems is "visibility"—knowing exactly what a task is doing at any given moment. To address this, the implementation utilizes Huey’s signal decorators. By creating a structured event log that captures signals for task execution, completion, and failure, developers build a real-time monitoring system. This log tracks essential metadata, including task IDs, arguments, and exception details, providing a trail for debugging and performance auditing.
3. Task Definition and Priority Management
The core of the system lies in its ability to handle diverse workloads. Tasks are categorized by their resource demands and reliability requirements:
- High-Priority Tasks: Simple arithmetic or urgent notifications assigned a high priority value to ensure they jump to the front of the queue.
- I/O-Bound Tasks: Simulated network calls or file operations that use
time.sleepto represent latency. - Fault-Tolerant Tasks: "Flaky" operations that are programmed with automated retry logic and exponential backoff, ensuring that transient network failures do not result in permanent task loss.
- CPU-Bound Tasks: Computationally heavy operations, such as Monte Carlo simulations for estimating Pi, which demonstrate how the consumer handles intensive processing without blocking the main application thread.
Advanced Workflow Patterns: Locking and Pipelines
As systems scale, the need for sophisticated task orchestration becomes apparent. Simple queues are often insufficient for workflows that require strict sequencing or mutual exclusion.
Mutex Locking for Data Integrity
In scenarios where multiple tasks might attempt to modify the same resource simultaneously—such as a daily synchronization job—Huey provides a locking mechanism. By applying a @huey.lock_task decorator, the system ensures that only one instance of a specific task runs at a time. This prevents race conditions and ensures data integrity in sensitive operations.
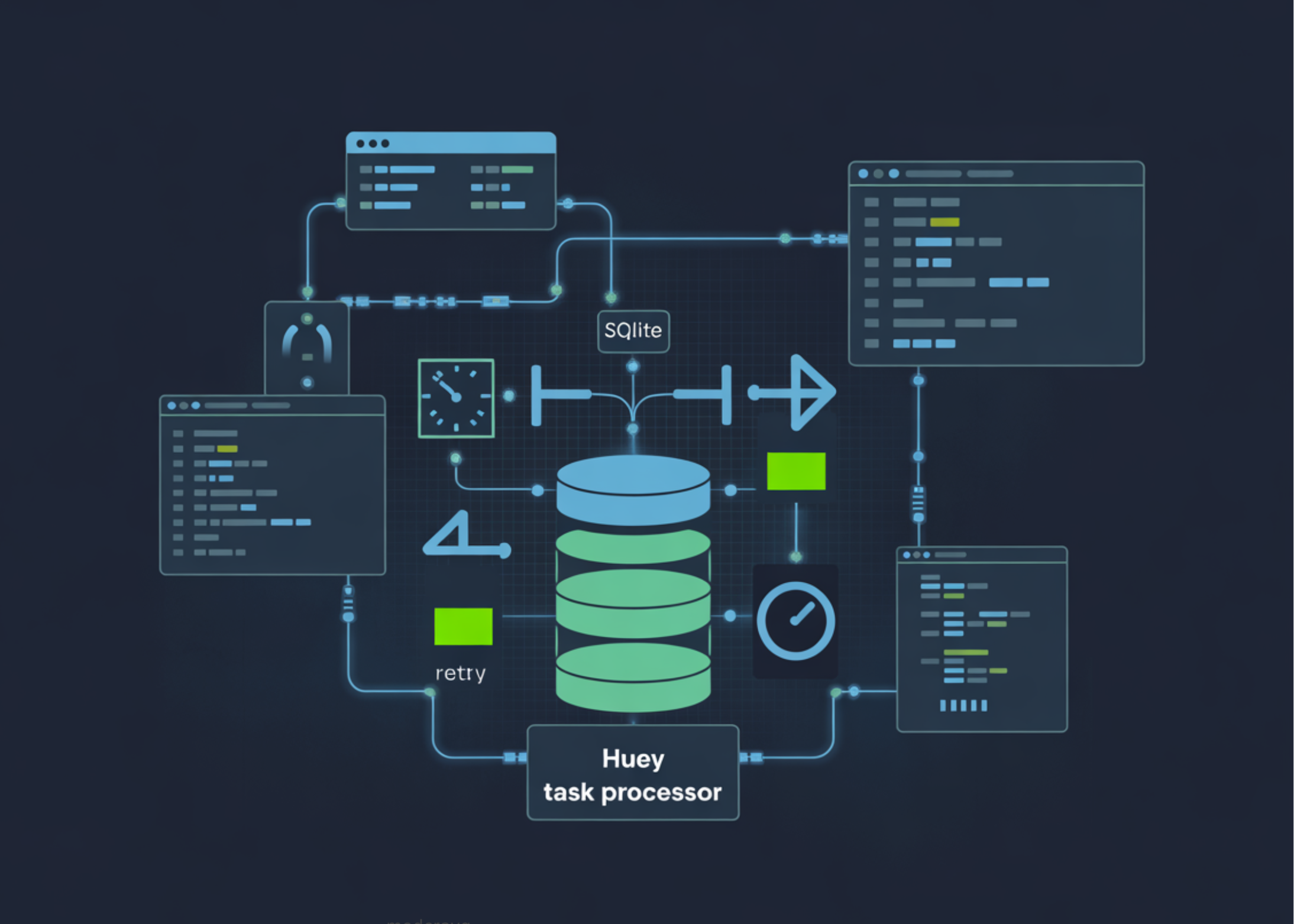
Task Chaining and Pipelines
Modern applications often require "pipelines," where the output of one task serves as the input for the next. The Huey-SQLite implementation supports structured workflows through a "chaining" API. For instance, a pipeline might involve fetching a raw number, transforming it through a scaling function, and finally storing the result in a database. This modular approach allows developers to build complex business logic from simple, reusable task components.
Periodic Scheduling and Heartbeat Mechanisms
A robust background system must handle not only reactive tasks but also proactive, scheduled events. Huey’s integration with crontab-style scheduling allows for minute-by-minute task execution.
To ensure system health, developers often implement a "heartbeat" task. In the SQLite-backed model, this involves a periodic task that increments a counter or logs a timestamp. For sub-minute intervals—which are not natively supported by standard crontabs—a threaded timer mechanism can be used to enqueue heartbeat tasks every few seconds. This provides a visible stream of activity, confirming that the consumer is alive and the SQLite backend is successfully processing enqueued jobs.
Performance Analysis and Supporting Data
While SQLite is often perceived as a "lite" database, its performance in task-queueing scenarios is remarkably robust. According to internal benchmarks and community testing, a SQLite-backed queue in WAL mode can handle hundreds of task insertions per second on standard SSD hardware.
| Feature | SQLite Backend | Redis Backend |
|---|---|---|
| Setup Complexity | Zero (Single file) | Moderate (Server required) |
| Persistence | Native/Immediate | Configurable/Snapshot-based |
| Memory Usage | Low (Disk-based) | High (In-memory) |
| Latency | 1–5ms (Disk I/O) | <1ms (RAM) |
| Scalability | Small to Medium | High/Horizontal |
For developers working in cloud environments like Google Colab or AWS Lambda, the SQLite backend eliminates the cost of a managed Redis instance, which can range from $15 to $100 per month depending on the provider. The "self-contained" nature of the SQLite file also simplifies CI/CD pipelines, as the entire environment can be replicated by simply copying the database.
Official Responses and Developer Sentiment
While there is no "official" corporate statement on Huey, as it is an open-source project, the sentiment among the Python developer community has shifted toward "Boring Technology"—a term coined by Dan McKinley to describe stable, well-understood tools.
Senior architects have noted that for approximately 80% of web applications, the overhead of Redis or RabbitMQ is unnecessary. "The ability to run a full production-grade queue inside a Jupyter notebook or a small VPS using nothing but the standard library and Huey is a game-changer for rapid prototyping," noted one data engineering lead. The consensus is that while Redis remains king for high-throughput, sub-millisecond requirements, SQLite is the superior choice for operational simplicity.
Broader Impact and Industry Implications
The successful demonstration of a SQLite-backed background task system has significant implications for the future of decentralized and edge computing. As more logic moves to the edge—closer to the end-user—the ability to run complex asynchronous workflows without a central server becomes vital.
Furthermore, this approach democratizes high-quality software patterns. Small teams and individual developers can now implement "enterprise" features like task priorities, retries, and scheduled pipelines with minimal financial investment. This lowers the barrier to entry for building resilient, scalable applications.
In a broader context, the reliance on SQLite for task queueing mirrors the growth of other "SQLite-first" tools like PocketBase or LiteFS. It signals a move away from the "microservices sprawl" of the last decade toward more integrated, maintainable, and cost-effective software architectures.
Conclusion: Toward a More Efficient Asynchronous Future
The exploration of Huey and SQLite as a background task processing system reveals a powerful truth in software engineering: complexity is not a prerequisite for capability. By leveraging the ACID compliance of SQLite and the feature-rich API of Huey, developers can manage sophisticated asynchronous workloads, ensure task reliability through retries and locking, and maintain high observability through signal-based monitoring.
As the industry continues to evaluate the trade-offs between performance and simplicity, the SQLite-backed model stands as a compelling alternative for those seeking to minimize infrastructure debt while maintaining production-grade standards. Whether deployed in a cloud notebook for data science or a production web server for background job handling, this architecture provides a blueprint for efficient, modern Python development.