This second-generation model succeeds the text-only gemini-embedding-001 and is designed specifically to address the high-dimensional storage and cross-modal retrieval challenges faced by AI developers building production-grade Retrieval-Augmented Generation (RAG) systems. The release of Gemini Embedding 2 marks a significant technical shift in how embedding models are architected, moving away from modality-specific pipelines toward a unified, natively multimodal latent space. By allowing developers to convert disparate data types—ranging from legal PDFs to raw video footage—into a single mathematical representation, Google is positioning this model as a cornerstone for the next generation of "agentic" artificial intelligence applications that must perceive the world in its full complexity.
The Evolution of the Gemini Ecosystem
The trajectory of Google’s AI development has been characterized by a steady move toward consolidation. In the early stages of the generative AI boom, developers were forced to stitch together a "Frankenstein" of models: one for processing text (such as BERT or RoBERTa), another for image recognition (like CLIP), and yet another for audio transcription (like Whisper). While functional, these pipelines were fragile and often lost semantic nuances during the translation between different model architectures.
With the introduction of the Gemini family in late 2023 and early 2024, Google signaled its intent to build "natively multimodal" systems from the ground up. Gemini Embedding 2 represents the realization of this vision for the vector database layer. Unlike its predecessor, which focused exclusively on textual data, the new model is trained on a massive, heterogeneous dataset that includes billions of tokens across various media types. This allows the model to understand that the concept of a "sunset" is the same whether it is described in a poem, captured in a JPEG, or filmed in a 10-second MP4 clip.
Native Multimodality and the Unified Latent Space
The primary architectural advancement in Gemini Embedding 2 is its ability to map five distinct media types—Text, Image, Video, Audio, and PDF—into a single, high-dimensional vector space. In technical terms, this creates a unified latent space where the distance between vectors represents semantic similarity regardless of the input’s original format.
The model supports interleaved inputs, a feature that is particularly relevant for modern RAG use cases where text alone does not provide sufficient context. For example, a developer building a customer support bot for a hardware company can now embed a technical manual (PDF) alongside a video tutorial of a repair and a text description of a specific error code. When a user asks a question, the system can retrieve the most relevant "chunk" of data, whether that chunk is a specific paragraph, a frame from the video, or a diagram from the PDF.
The technical specifications for these inputs are expansive. The model is capable of processing thousands of tokens of text while simultaneously analyzing visual and auditory signals. By processing these inputs natively, Gemini Embedding 2 captures the semantic relationships between a visual frame in a video and the spoken dialogue in an audio track, projecting them as a single vector that can be compared against text queries using standard distance metrics like Cosine Similarity or Dot Product.
Efficiency via Matryoshka Representation Learning
One of the most significant barriers to scaling AI search systems is the "curse of dimensionality." High-quality embeddings typically require thousands of dimensions to capture the nuances of human language and visual data. However, storing and searching through billions of 3,072-dimension vectors is computationally expensive and requires significant memory overhead in vector databases like Pinecone, Milvus, or Weaviate.
To mitigate this, Gemini Embedding 2 implements Matryoshka Representation Learning (MRL). Named after the famous Russian nesting dolls, MRL is a training technique that forces the model to pack the most critical semantic information into the earliest dimensions of the vector.
In standard embedding models, information is distributed evenly across all dimensions. If a developer truncates a 3,072-dimension vector to 768 dimensions to save space, the accuracy typically collapses because essential data is lost. In contrast, Gemini Embedding 2 is optimized to maintain high performance even when truncated. Google has optimized three specific tiers for production use:

- 3,072 Dimensions: The full-fidelity vector for maximum accuracy in complex reasoning tasks.
- 768 Dimensions: A balanced tier that offers a 4x reduction in storage costs with minimal impact on retrieval precision.
- 256 and 128 Dimensions: Ultra-compressed tiers designed for high-speed "short-listing" or edge-device applications.
This "short-listing" architecture allows a system to perform a coarse, high-speed search across millions of items using the 768-dimension sub-vectors, then perform a precise re-ranking of the top results using the full 3,072-dimension embeddings. This tiered approach reduces the computational overhead of the initial retrieval stage without sacrificing the final accuracy of the RAG pipeline, effectively solving the trade-off between speed and precision.
Benchmarking and Performance Metrics
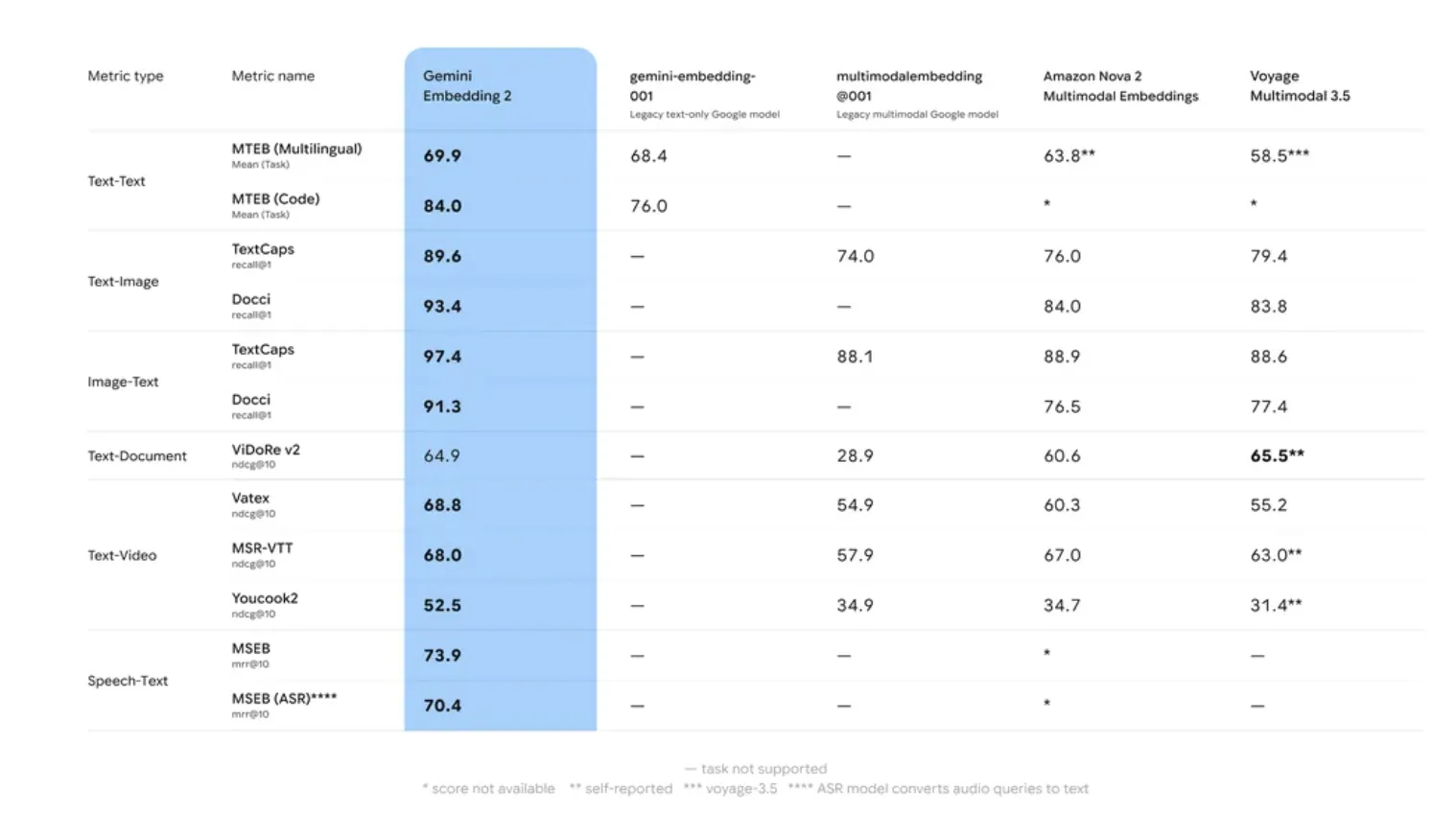
Google’s internal evaluations and performance on the Massive Text Embedding Benchmark (MTEB) indicate that Gemini Embedding 2 significantly outperforms its predecessor and remains competitive with industry leaders like OpenAI’s text-embedding-3-large.
The model excels in two specific areas: Retrieval Accuracy and Robustness to Domain Shift. "Domain drift" is a common failure point in AI where a model trained on general data (like Wikipedia or Reddit) fails to understand specialized language (like legal contracts or medical records). Gemini Embedding 2 utilized a multi-stage training process involving diverse datasets to ensure higher zero-shot performance across specialized tasks.
Furthermore, the model’s 8,192-token window is a critical specification for enterprise RAG. Traditional embedding models often have smaller windows (e.g., 512 or 1,024 tokens), requiring developers to break documents into tiny snippets. This often leads to "context fragmentation," where a retrieved snippet lacks the necessary surrounding information to be useful. The 8,192-token window allows for the embedding of larger "chunks," preserving the context necessary for resolving coreferences and long-range dependencies within a document.
Industry Implications and Market Reaction
The release has sparked considerable interest among enterprise developers and AI researchers. Industry analysts suggest that Google’s move to integrate PDF and video natively into the embedding space addresses a major pain point in corporate data processing. Most corporate knowledge is locked away in unstructured formats like slide decks and recorded meetings. By providing a native way to search these formats, Google is lowering the barrier to entry for companies looking to build internal AI "brains."
While competitors like OpenAI and Cohere offer robust text embedding models, the "all-in-one" multimodal approach of Gemini Embedding 2 provides a streamlined developer experience. Early feedback from the developer community suggests that the reduction in pipeline complexity—eliminating the need for separate OCR (Optical Character Recognition) and video-to-text transcription steps before embedding—could lead to significant savings in both development time and API costs.
However, some experts remain cautious regarding the privacy implications of embedding diverse media types. As models become more capable of "seeing" and "hearing" the data they process, the importance of robust data governance and anonymization becomes paramount. Google has addressed these concerns by integrating the model into Vertex AI, which provides enterprise-grade security and compliance features.
Chronology of Google’s Embedding Strategy
The launch of Gemini Embedding 2 is the latest step in a multi-year strategy to dominate the AI infrastructure layer:
- Late 2022: Google releases early versions of its text embedding models for internal use and limited Vertex AI preview.
- December 2023: The original Gemini 1.0 Pro is announced, alongside the first-generation gemini-embedding-001, which focused on text-only RAG.
- Mid-2024: Google introduces Gemini 1.5 Pro with a million-token context window, highlighting the need for more sophisticated retrieval mechanisms to handle massive data inputs.
- Early 2026: Gemini Embedding 2 is released in Public Preview, marking the transition to native multimodality and MRL-optimized efficiency.
Conclusion and Availability
Gemini Embedding 2 represents a milestone in the maturation of RAG technology. By treating text, images, video, audio, and documents as equal citizens in the embedding space, Google is enabling a more holistic approach to data retrieval. The implementation of Matryoshka Representation Learning further ensures that these advancements are accessible at scale, allowing developers to balance performance with the economic realities of cloud storage and compute.
The model is currently available in Public Preview via the Gemini API and through Google Cloud’s Vertex AI platform. As the AI industry continues to shift from simple chat interfaces to complex, data-driven agents, the ability to accurately retrieve and understand multimodal information will likely become the defining feature of successful AI implementations.