Liquid AI, the MIT spinoff specializing in efficient, high-performance artificial intelligence architectures, has announced the official release of LFM2.5-VL-450M. This new vision-language model (VLM) represents a significant iterative leap over its predecessor, the LFM2-VL-450M, packing advanced capabilities including spatial grounding via bounding box prediction, enhanced multilingual comprehension, and function calling into a compact 450-million-parameter framework. By optimizing for edge hardware, Liquid AI is positioning this model as a critical tool for real-time applications in robotics, mobile technology, and industrial automation, where reliance on cloud-based processing is often prohibited by latency requirements or privacy concerns.
The release of LFM2.5-VL-450M comes at a time when the broader AI industry is shifting its focus from massive, multi-billion parameter models toward highly efficient Small Language Models (SLMs) and specialized vision-language tools. While frontier models like GPT-4o or Gemini 1.5 Pro offer immense reasoning capabilities, their computational demands necessitate massive data center resources. In contrast, Liquid AI’s latest offering is specifically designed to run locally on devices such as the NVIDIA Jetson Orin for robotics, the AMD Ryzen AI Max+ 395 for next-generation PCs, and the Qualcomm Snapdragon 8 Elite found in flagship mobile devices like the Samsung S25 Ultra.
Technical Architecture and Training Methodology
The LFM2.5-VL-450M is built upon a hybrid architecture that balances linguistic reasoning with visual perception. At its core, the model utilizes the LFM2.5-350M as its language backbone, integrated with the SigLIP2 NaFlex shape-optimized 86M vision encoder. This combination allows for a sophisticated understanding of the relationship between textual prompts and visual data. The model features a context window of 32,768 tokens and a vocabulary size of 65,536, providing it with the memory capacity to handle complex, multi-turn instructions.
One of the most notable technical achievements in this version is its approach to image processing. Traditional VLMs often struggle with non-standard aspect ratios or high-resolution images, frequently resorting to aggressive downscaling that destroys fine details. LFM2.5-VL-450M addresses this through a native resolution strategy that supports processing up to 512×512 pixels without upscaling. For larger images, the model employs a sophisticated tiling strategy, dividing the input into non-overlapping 512×512 patches.
Crucially, the architecture includes "thumbnail encoding," a global context layer that ensures the model retains an understanding of the overall scene while analyzing localized patches. This prevents the "tunnel vision" effect common in tiled processing, where a model might recognize a specific object but fail to understand its spatial relationship to the rest of the environment. Furthermore, Liquid AI has designed the inference engine to allow users to tune the maximum image tokens and tile count dynamically. This enables developers to balance speed and quality based on the specific hardware constraints of the deployment environment without the need for retraining.
The training pipeline for LFM2.5-VL-450M was substantially expanded compared to previous iterations. Liquid AI increased the pre-training scale from 10 trillion to 28 trillion tokens. Following this massive data ingestion phase, the model underwent rigorous post-training using preference optimization and reinforcement learning. These steps were specifically targeted at improving the model’s grounding—its ability to link words to specific visual elements—and its reliability in following complex, multi-step instructions.

Advanced Capabilities and Spatial Grounding
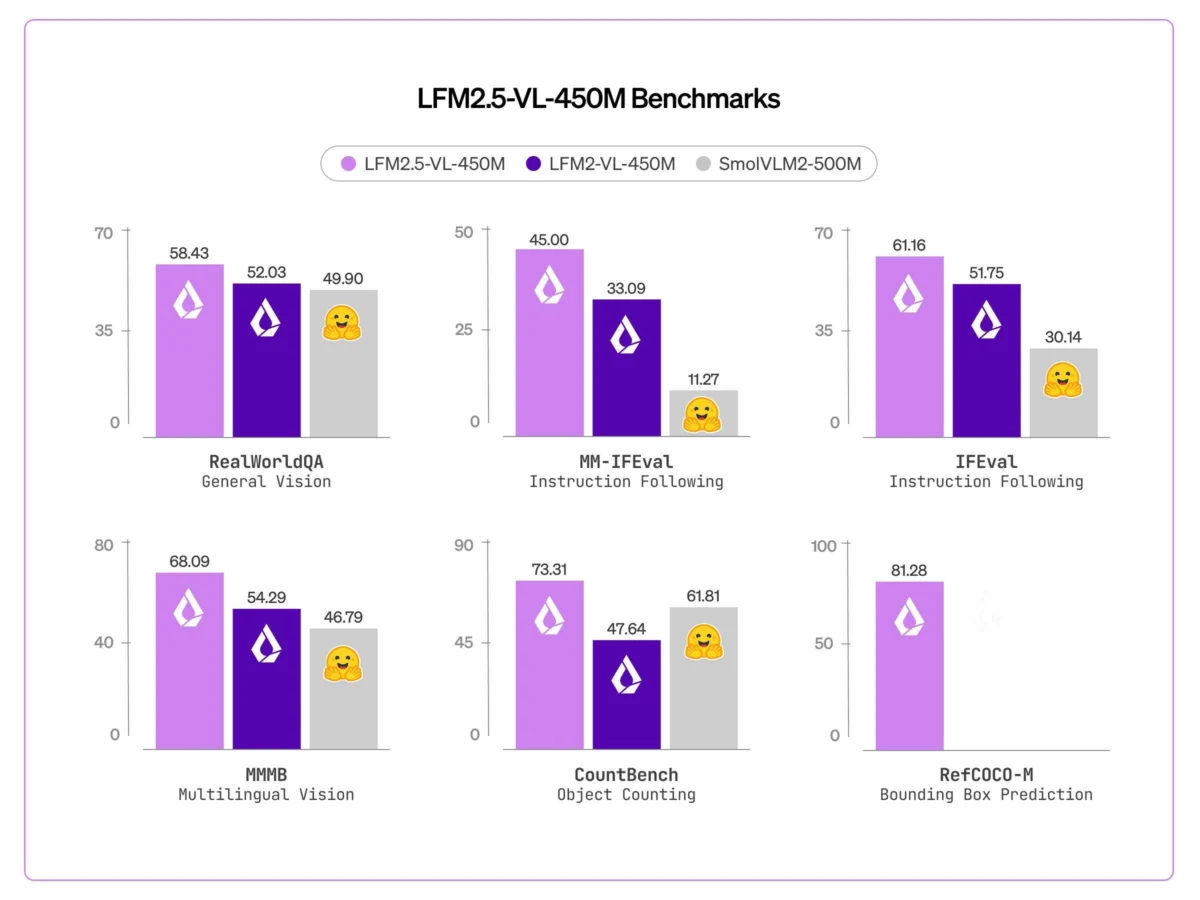
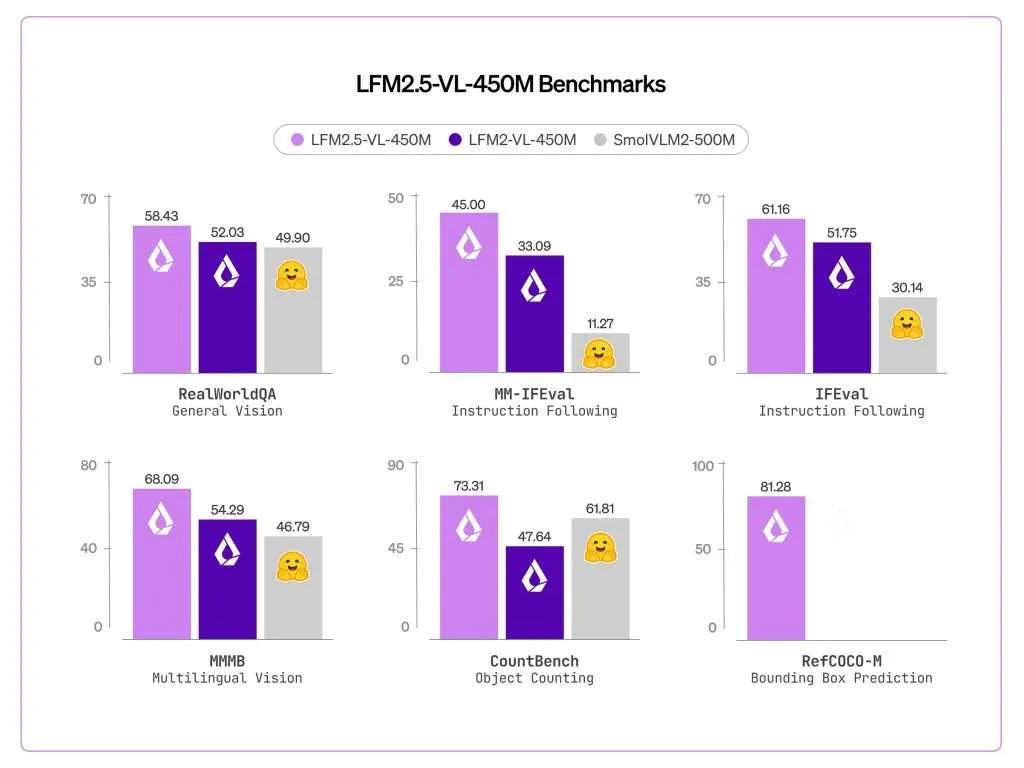
The introduction of bounding box prediction is perhaps the most transformative feature of the LFM2.5-VL-450M. In the previous version, the model could describe a scene but lacked the precision to locate specific objects within it. The new model achieved a score of 81.28 on the RefCOCO-M benchmark, a visual grounding metric that was essentially zero in the prior version. By outputting structured JSON data containing normalized coordinates, the model can now pinpoint exactly where an object resides in a frame.
This capability transitions the model from a simple descriptive tool to an actionable perception engine. In a warehouse setting, for example, the model does not just report "there is a forklift"; it can provide the exact coordinates of that forklift, allowing a control system to navigate around it. This spatial awareness is vital for any application involving physical interaction or detailed monitoring.
Multilingual support has also seen a dramatic improvement. The model now scores 68.09 on the MMMB benchmark, up from 54.29. This improvement covers a broad spectrum of languages, including Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish. For global enterprises, this means a single model can be deployed across different regions, understanding local prompts and visual cues without requiring separate, localized translation pipelines.
Instruction following, measured by the MM-IFEval benchmark, rose from 32.93 to 45.00. This suggests that the model is significantly better at adhering to specific formatting requests or restrictive output conditions. Additionally, Liquid AI added function calling support for text-only inputs, achieving a BFCLv4 score of 21.08. Function calling allows the model to act as an agent, triggering external APIs or downstream system actions based on the information it processes, such as querying a database or adjusting a smart home setting.
Performance Benchmarks and Edge Inference
Liquid AI utilized the VLMEvalKit to evaluate the LFM2.5-VL-450M against several industry standards, consistently outperforming both its predecessor and competitors like the SmolVLM2-500M. Key performance indicators include:
- POPE (Object Hallucination): 86.93
- OCRBench (Text Recognition): 684
- MMBench (General Vision-Language): 60.91
- RealWorldQA (Real-world Understanding): 58.43
- CountBench (Object Counting): 73.31 (a massive jump from 47.64 in the previous version)
While the model showed slight retreats in specific knowledge-intensive tasks—such as a minor drop in MMMU scores from 34.44 to 32.67—Liquid AI remains transparent about the model’s limitations. It is not intended to be a general-purpose encyclopedia; rather, it is a high-speed perception and reasoning engine for immediate, context-aware tasks.
The latency data provided by Liquid AI underscores the model’s readiness for real-time deployment. On the NVIDIA Jetson Orin, a staple in the robotics industry, the model maintains sub-250ms latency for both 256×256 and 512×512 image resolutions. This speed allows for processing at roughly 4 frames per second (FPS), providing a continuous stream of semantic understanding that is far more detailed than simple object detection. On consumer-grade hardware, the performance remains impressive. The AMD Ryzen AI Max+ 395 handles 256×256 images in 637ms, while the Snapdragon 8 Elite inside the Samsung S25 Ultra processes them in 950ms. These sub-second response times are critical for maintaining a "snappy" user experience in interactive mobile AI applications.
Chronology of Development and Market Context
The trajectory of Liquid AI has been characterized by a rapid pace of innovation. The company, which emerged from the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL), initially gained attention for its "Liquid Neural Networks." These are a class of AI models inspired by the brains of small organisms, designed to be more adaptable and efficient than traditional transformer-based architectures.
The LFM (Liquid Foundation Model) series has evolved through several key stages:
- LFM-1.0: Established the proof of concept for high-efficiency language modeling.
- LFM2-VL-450M: Introduced the first vision-language capabilities in the 450M parameter class.
- LFM2.5-VL-450M: The current release, which refines the architecture, triples the training data, and introduces critical spatial grounding and agentic features.
This progression reflects a clear strategic goal: to dominate the "Edge AI" market. As privacy regulations like the EU AI Act become more stringent, the ability to process sensitive visual data—such as security footage or medical imagery—locally on a device becomes a competitive advantage. By removing the need to transmit data to the cloud, Liquid AI reduces both the risk of data breaches and the high costs associated with server-side inference.
Broader Impact and Industrial Implications
The implications of LFM2.5-VL-450M extend across several major industries. In industrial automation and robotics, the model’s ability to run on a Jetson Orin allows for a new generation of "smart" robots. These machines can do more than just follow pre-programmed paths; they can understand complex natural language instructions and locate objects dynamically in their environment.
In the realm of wearable technology, such as smart glasses or body-worn cameras for law enforcement and emergency services, the model’s efficiency is a game-changer. These devices have limited battery life and thermal budgets, making large models impractical. LFM2.5-VL-450M provides the necessary intelligence to describe scenes or identify hazards without draining the device’s battery in minutes.
The retail sector also stands to benefit significantly. From automated shelf compliance—where a camera can identify missing stock and its precise location—to enhanced visual search in e-commerce, the model provides a cost-effective way to deploy high-level visual reasoning at scale.
As Liquid AI continues to refine its "liquid" architectures, the LFM2.5-VL-450M serves as a benchmark for what is possible at the intersection of small-scale computing and large-scale intelligence. By proving that a 450M parameter model can rival much larger systems in specific, real-world tasks, Liquid AI is challenging the "bigger is better" paradigm that has dominated the AI landscape for the past decade. The focus is now shifting toward "smarter and smaller," a transition that LFM2.5-VL-450M is uniquely positioned to lead.