




The Evolution of the Mistral Ecosystem: A Chronology of Development
The arrival of Mistral Small 4 represents a mature phase in Mistral AI’s rapid ascent within the global artificial intelligence landscape. Founded in early 2023 by former researchers from Meta and Google DeepMind, the Paris-based company initially gained international recognition for its high-performance, open-weights models that prioritized efficiency over raw parameter count.
In September 2023, the company released Mistral 7B, which set a new standard for small-scale language models. This was followed in December 2023 by Mixtral 8x7B, a pioneer in the "Mixture-of-Experts" (MoE) architecture that allowed for high intelligence with lower computational requirements during inference. Throughout 2024, Mistral diversified its portfolio, launching "Mistral Large" for enterprise-grade reasoning, "Pixtral" for vision-language tasks, and "Codestral" (later evolving into Devstral) for programming.
Mistral Small 3, the predecessor to the current release, focused heavily on instruction following and efficiency. However, as the industry moved toward "omni" models—systems capable of handling text, code, and images simultaneously—Mistral’s fragmented lineup began to present integration challenges for engineering teams. The release of Mistral Small 4 is the direct strategic response to this fragmentation, marking a shift toward architectural unification and "agentic" readiness.
Architectural Deep Dive: 128 Experts and Sparse Activation
At the core of Mistral Small 4 is a highly refined Mixture-of-Experts (MoE) architecture. Unlike dense models where every parameter is activated for every token, MoE models utilize a gating mechanism to route tasks to specific "experts" within the network. Small 4 features a total of 119 billion parameters, yet it operates with remarkable efficiency.
The model utilizes 128 individual experts, with only 4 experts activated per token during inference. This results in approximately 6 billion active parameters per token, expanding to roughly 8 billion when accounting for embedding and output layers. This sparse activation allows the model to maintain the intellectual "breadth" of a 100B+ parameter system while offering the latency and throughput characteristics typically associated with much smaller models.
Furthermore, the model introduces a 256k context window. In the current competitive landscape, context windows have often been used as marketing metrics, but Mistral emphasizes the practical engineering utility of this capacity. A 256k window enables the model to ingest entire codebases, long-form legal documents, or extensive chat histories without the need for aggressive Retrieval-Augmented Generation (RAG) orchestration or lossy text chunking. This is particularly vital for agentic workflows where the model must maintain state across a long series of interactions and tool calls.
Configurable Reasoning: Balancing Latency and Depth
One of the most notable technical innovations in Mistral Small 4 is the introduction of a "configurable reasoning effort" parameter. This feature allows developers to adjust the model’s cognitive intensity on a per-request basis via the reasoning_effort API parameter.
The industry has recently seen a trend toward "test-time compute" or "inference-time reasoning," where models are given more time to "think" before generating a final response. Mistral Small 4 formalizes this by offering a spectrum of effort:
- Reasoning Effort "None": The model operates in a high-speed, conversational mode similar to Mistral Small 3.2. This is optimized for simple chat, basic summarization, and low-latency interactions.
- Reasoning Effort "High": The model engages in deliberate, step-by-step reasoning. This mode is designed for complex mathematical proofs, intricate coding logic, and nuanced multi-step problem solving, mirroring the performance of the earlier "Magistral" reasoning-focused models.
From a systems architecture perspective, this is a significant improvement over traditional routing methods. Previously, a developer might have to use a "classifier" model to determine the difficulty of a prompt and then route it to either a fast model or a slow reasoning model. Mistral Small 4 removes this complexity by allowing the same model to scale its internal effort based on the specific needs of the query.
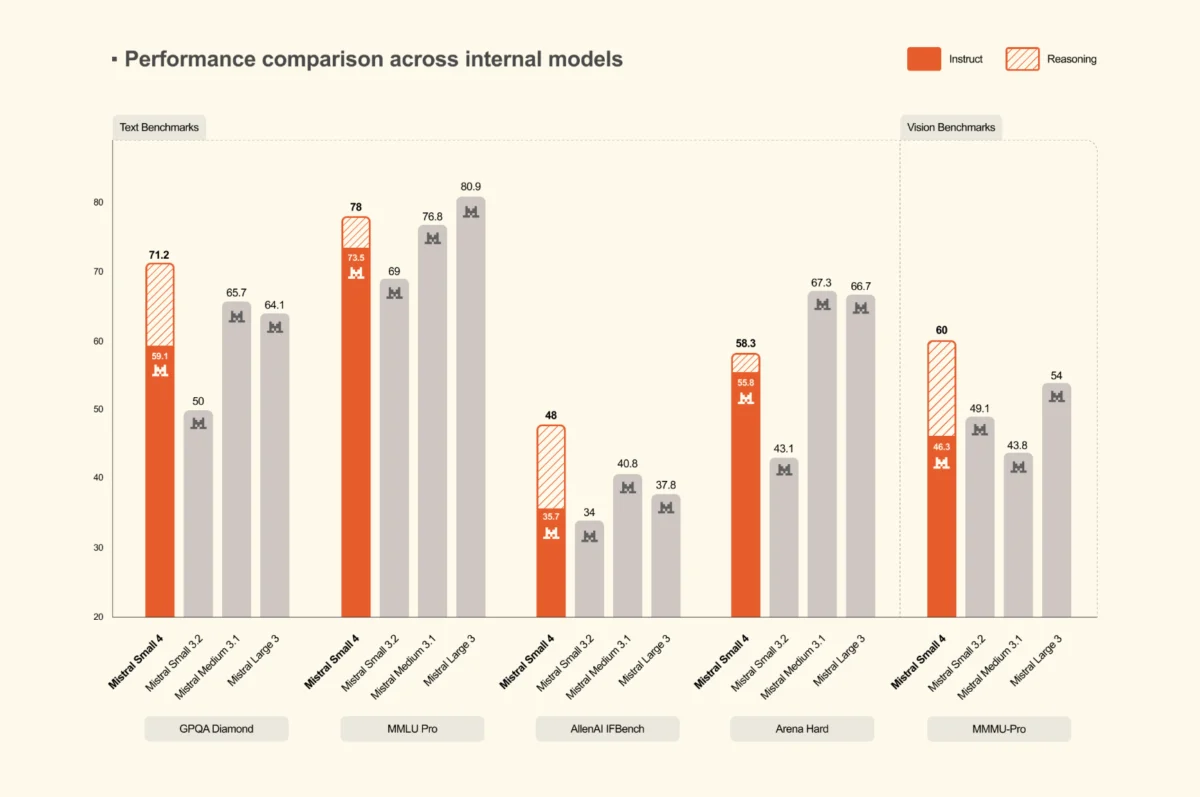
Benchmark Performance and Output Efficiency
In benchmarking data released alongside the model, Mistral AI focuses on a metric that is often overlooked in academic evaluations: performance per generated token. While many models achieve high scores by generating verbose, lengthy explanations, Mistral Small 4 is designed for "output efficiency."

On reasoning benchmarks such as AA LCR, LiveCodeBench, and AIME 2025, Mistral Small 4 with reasoning enabled was compared against GPT-OSS 120B and various Qwen models. The data suggests that Small 4 matches or exceeds the performance of these competitors while producing significantly shorter outputs. For example, on the AA LCR benchmark, Small 4 achieved a score of 0.72 using only 1.6K characters, whereas comparable Qwen models required between 5.8K and 6.1K characters to reach similar accuracy levels.
On LiveCodeBench, a standard for evaluating coding proficiency, Small 4 outperformed GPT-OSS 120B while generating 20% less text. This brevity is not merely a stylistic choice; it has direct implications for enterprise deployment. Shorter outputs lead to:
- Lower Latency: Fewer tokens generated means the user receives the answer faster.
- Reduced Cost: Most AI providers and internal infrastructure teams charge or budget based on token counts.
- Cleaner Parsing: For agentic systems that use the model’s output to trigger tools or code execution, concise and accurate responses reduce the likelihood of parsing errors.
Infrastructure and Deployment Considerations
Mistral AI has provided clear guidance for organizations looking to self-host Mistral Small 4, acknowledging the model’s substantial footprint despite its MoE efficiency. The model is positioned for high-end enterprise hardware.
The minimum recommended deployment targets include:
- 4x NVIDIA HGX H100: For standard production workloads.
- 2x NVIDIA HGX H200: Leveraging higher VRAM for increased throughput.
- 1x NVIDIA DGX B200: Utilizing NVIDIA’s latest Blackwell architecture for maximum efficiency.
On the software side, Mistral Small 4 is launching with broad support across the open-source serving ecosystem. The model card on HuggingFace confirms compatibility with vLLM, llama.cpp, SGLang, and the HuggingFace Transformers library. vLLM is currently the recommended engine for production environments. Mistral also noted that they are actively upstreaming fixes to handle the specific parsing requirements of the new reasoning and tool-calling features, signaling a commitment to the "open-weights" community.
Industry Implications and Market Analysis
The release of Mistral Small 4 signals a broader shift in the AI industry toward the "Model Unification" era. As AI applications move from simple chatbots to complex autonomous agents, the requirement for a model to "see," "code," "reason," and "follow instructions" simultaneously has become paramount.
By merging Pixtral (vision) and Devstral (coding) into the Small 4 architecture, Mistral is positioning itself to compete directly with closed-source giants like OpenAI’s GPT-4o and Anthropic’s Claude 3.5 Sonnet. The move is particularly strategic for the European market and for global enterprises that require data sovereignty. These organizations often prefer open-weights models that can be hosted on-premises or in private clouds but have previously struggled with the complexity of managing multiple specialized models.
Industry analysts suggest that the "configurable reasoning" feature is a direct response to OpenAI’s "o1" series. By allowing developers to toggle reasoning effort, Mistral provides a level of control over the "Compute-Reasoning-Latency" triangle that is highly attractive for cost-sensitive enterprise applications.
Furthermore, the focus on output efficiency highlights a maturing understanding of AI economics. As the "hype" phase of AI gives way to the "implementation" phase, the ability to deliver high-quality reasoning with fewer tokens becomes a primary competitive advantage.
Conclusion and Future Outlook
Mistral Small 4 represents a consolidation of Mistral AI’s technical achievements over the past two years. By delivering a 119B MoE model that handles multimodal, reasoning, and coding tasks within a 256k context window, the company has provided a robust alternative to the dominant closed-source models.
The emphasis on deployment economics—specifically through increased throughput and shorter, more efficient outputs—suggests that Mistral is focusing on the practical realities of AI at scale. As the model stabilizes within the open-source ecosystem and more developers adopt the reasoning_effort parameter, the impact of this "unified" approach will likely influence how other model developers structure their future releases. For now, Mistral Small 4 stands as a testament to the power of architectural efficiency and the ongoing viability of the open-weights model in the global AI race.













