



The Challenge of Linguistic Representation in Africa
Africa is home to approximately one-third of the world’s languages, representing a staggering level of phonetic and grammatical diversity. However, the continent’s linguistic richness has often been a barrier to digital inclusion. Developing speech technology for African languages involves overcoming several hurdles, including the lack of standardized orthographies for some tongues, a scarcity of digitized text, and the high cost of high-quality audio collection. Prior to the release of WAXAL, most open datasets for African languages were either too small for deep learning applications or lacked the necessary phonetic coverage to produce natural-sounding synthetic voices.
Google’s WAXAL project seeks to move beyond the limitations of "crawled" data—audio scraped from the internet that often lacks metadata or clean transcriptions. By employing a ground-up collection strategy, the researchers have ensured that the data is not only accurate but also representative of the way people actually speak in their daily lives. The initiative aligns with broader industry movements, such as Mozilla’s Common Voice and the Masakhane research community, which aim to democratize AI and ensure that the benefits of speech-to-text and text-to-speech tools are accessible to the African diaspora and those living on the continent.
Strategic Separation: Why ASR and TTS Require Different Data
One of the most technically significant aspects of the WAXAL dataset is its dual-path architecture. The research team recognized that ASR and TTS systems serve fundamentally different purposes and therefore have conflicting data requirements.
ASR systems must be "robust," meaning they need to understand speech regardless of background noise, speaker accent, or grammatical slips. To achieve this, the ASR component of WAXAL focuses on diversity. It includes recordings from a wide variety of speakers in natural environments, capturing the nuances of spontaneous language production. This "in-the-wild" approach ensures that models trained on WAXAL can function in real-world scenarios, such as voice-activated mobile services or automated transcription for healthcare and legal settings.
Conversely, TTS systems require "clean" data. The goal of TTS is to synthesize a voice that sounds human, consistent, and pleasant. If a TTS model is trained on noisy audio or speakers with inconsistent pacing, the resulting voice will often contain "artifacts"—unnatural robotic sounds or glitches. Consequently, the TTS side of WAXAL was developed under controlled conditions using professional voice actors and phonetically balanced scripts. This separation allows researchers to optimize for two different goals: recognition and synthesis, without compromising the quality of either.

Methodology for ASR Collection: Spontaneity and Context
The ASR portion of WAXAL was collected using an innovative "image-prompted" speech methodology. Instead of asking participants to read a prepared script—which often results in a formal, stiff tone—speakers were presented with images and asked to describe the scenes in their native language. This technique encourages the use of natural syntax and vocabulary, providing a more accurate reflection of colloquial speech.
The collection process was rigorous and highly documented. Key metrics tracked during the collection phase included:
- Speaker Demographics: Data on age, gender, and regional dialect to ensure model fairness.
- Recording Environments: Documentation of ambient noise levels to help researchers understand the model’s performance in different acoustic settings.
- Duration Requirements: Each recording was mandated to be at least 15 seconds long, providing enough audio context for modern transformer-based ASR architectures.
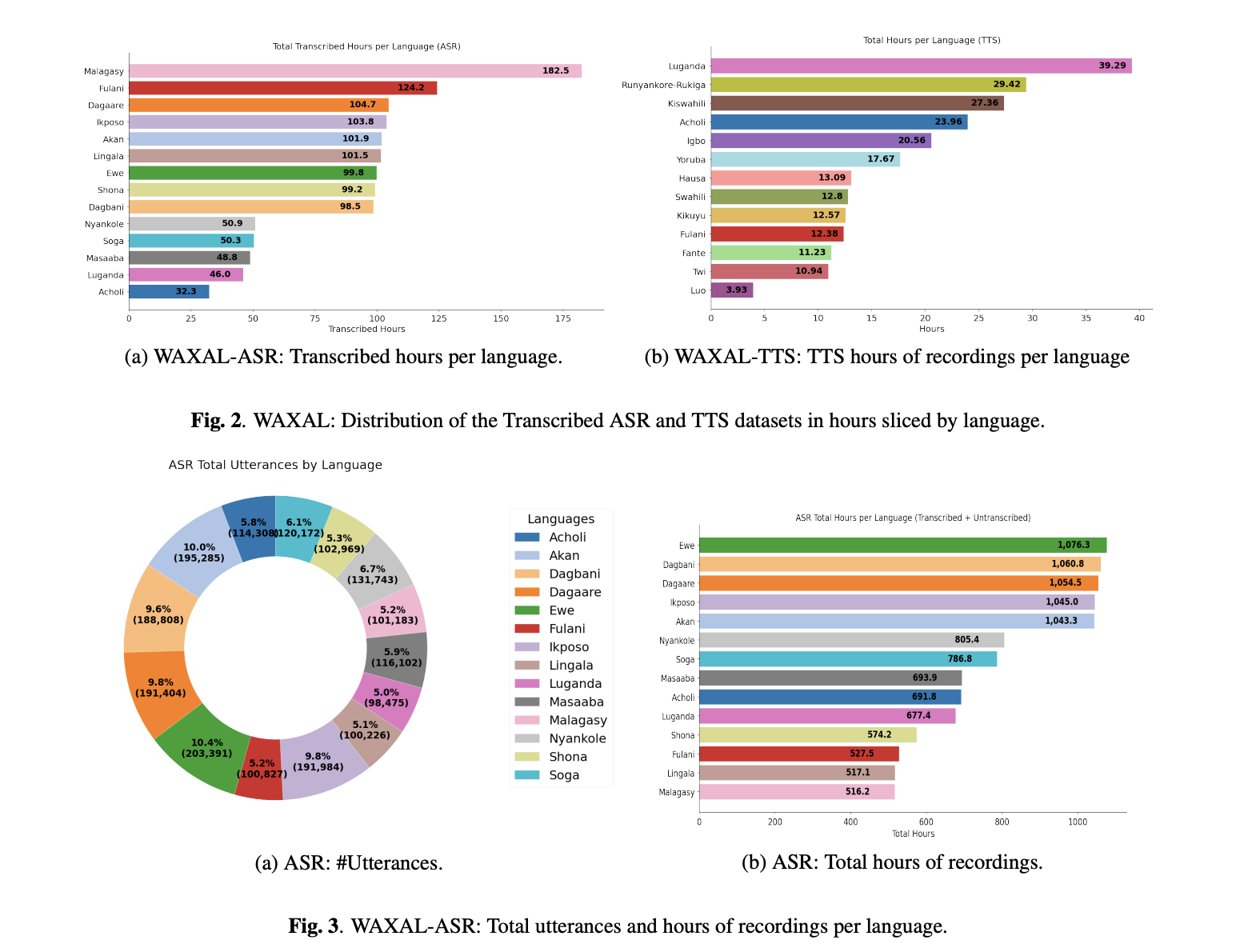
While the total volume of recorded audio is vast, the current release of WAXAL includes professional transcriptions for approximately 10% of the total audio. These transcriptions were handled by paid local linguistic experts who utilized local scripts where standardized orthographies exist. In cases where no standard script was available, the team used English-alphabet transliterations, ensuring the data remains usable for developers worldwide.
Methodology for TTS Collection: Precision and Fidelity
The TTS component of WAXAL was built with a focus on "high-resource" quality for "low-resource" languages. To create a dataset capable of producing high-quality synthetic voices, the team developed phonetically balanced scripts consisting of approximately 108,500 words for each target language. These scripts were designed to cover every possible phoneme and diphone (transitions between sounds) in the language, ensuring the AI learns how to pronounce even the rarest combinations of sounds.
For the recording phase, the project contracted 72 community participants. The team maintained a strict 50/50 gender balance between male and female voice actors to prevent gender bias in synthetic voice options. These actors recorded in professional, studio-like environments to minimize background interference. The target for each voice actor was 16 hours of clean, edited audio, resulting in a massive repository of high-fidelity speech. This volume of data is particularly valuable for training modern neural TTS models, which typically require dozens of hours of high-quality audio to achieve human-like prosody and intonation.
Chronology of the WAXAL Initiative
The development of WAXAL followed a multi-year timeline that reflects the complexity of large-scale linguistic data collection:
- Initial Scoping (Year 1): Identification of the 24 target languages based on speaker population, regional importance, and current data gaps.
- Partnership Building: Establishing relationships with local linguistic departments and community organizations across several African nations to ensure ethical data practices.
- The Collection Phase (Year 2): Deployment of recording tools and the recruitment of the 72 TTS voice actors and the much larger pool of ASR participants.
- Transcription and Validation (Year 3): Local experts began the laborious task of transcribing ASR audio and verifying the phonetic accuracy of TTS recordings.
- Open Source Release (Present): The dataset was finalized and hosted on platforms like Hugging Face, making it available to the global research community.
Technical Analysis of Broader Implications
The release of WAXAL has immediate implications for both the tech industry and the African continent. For developers, WAXAL provides a "gold standard" benchmark. Until now, researchers working on African languages often had to rely on small, fragmented datasets, making it difficult to compare the performance of different AI models. With WAXAL, there is now a common ground for evaluating ASR and TTS accuracy across two dozen languages.
From a socio-economic perspective, this dataset paves the way for "Voice-First" digital interfaces. In many parts of Africa, literacy rates and the prevalence of non-standardized scripts mean that voice interaction is often more intuitive than text-based interaction. By enabling better ASR and TTS, Google is facilitating the creation of apps that can help farmers get weather reports in Wolof, allow patients to receive medical advice in Yoruba, or enable students to learn in their mother tongue through educational software.
Furthermore, the focus on "image-prompted" speech for ASR is a major step forward in addressing "domain shift." Many AI models perform well on news broadcasts but fail when used by a regular person on a street corner. By capturing natural, descriptive speech, WAXAL helps bridge the gap between academic benchmarks and real-world utility.
Future Outlook and Scalability
While WAXAL covers 24 languages, the project is viewed as a foundational step rather than a final destination. The researchers have signaled that the methodology used—specifically the split between ASR and TTS and the use of image-prompted speech—can be scaled to hundreds of other languages.
There is also room for growth in the transcription of the remaining 90% of the ASR data. As "self-supervised learning" (SSL) becomes more prevalent in AI, even unlabelled audio becomes useful. Models like Google’s USM (Universal Speech Model) can use the unlabelled portions of WAXAL to learn the "sounds" of African languages, while the 10% of transcribed data serves as the "fine-tuning" signal that teaches the model how to map those sounds to text.
The open-source nature of WAXAL ensures that it will not remain static. By hosting the dataset on Hugging Face, Google has invited the global AI community to contribute, refine, and expand upon this work. This collaborative approach is essential for tackling the "data desert" and ensuring that the future of AI is as diverse as the human population it serves. As speech technology continues to integrate into every aspect of modern life, datasets like WAXAL ensure that millions of speakers across the African continent are not left behind in the silent corners of the digital world.